

Hoe zorgt u ervoor dat uw AI-oplossingen werken zoals u verwacht?
Een korte introductie tot AI-evaluaties
Generatieve AI (GenAI) ontwikkelt zich razendsnel en gaat niet langer alleen over leuke chatbots of indrukwekkende beeldgeneratie. 2025 is het jaar waarin de focus komt te liggen op het omzetten van de hype rondom AI in echte waarde. Bedrijven overal ter wereld zijn op zoek naar manieren om GenAI te integreren en te benutten in hun producten en activiteiten, om gebruikers beter van dienst te zijn, de efficiëntie te verbeteren, concurrerend te blijven en groei te stimuleren. Dankzij API's en vooraf getrainde modellen van toonaangevende aanbieders lijkt het integreren van GenAI eenvoudiger dan ooit. Maar hier is nu de kern van de zaak: Het feit dat integratie eenvoudig is, betekent niet dat AI-oplossingen na implementatie ook daadwerkelijk naar behoren werken.

Voorspellende modellen zijn niet echt nieuw: als mens voorspellen we al jaren dingen, officieel begonnen we met statistieken. Echter, GenAI zorgt om vele redenen voor een revolutie in de prognosebranche.:
- U hoeft geen eigen model te trainen of een datawetenschapper te zijn om AI-oplossingen te bouwen.
- AI is nu eenvoudig te gebruiken via chatinterfaces en eenvoudig te integreren via API's.
- Het maakt veel dingen mogelijk die voorheen niet mogelijk of heel moeilijk waren.
Al deze dingen maken GenAI is erg spannend, maar ook riskant.. In tegenstelling tot traditionele software – of zelfs klassiek machine learning – biedt GenAI een nieuw niveau van onvoorspelbaarheid. Je gebruikt geen deterministische logica, maar een model dat is getraind met enorme hoeveelheden data, in de hoop dat het op de juiste manier reageert. Hoe weten we nu of een AI-systeem doet wat wij willen? Hoe weten we of het klaar is voor gebruik? Het antwoord is evaluaties, een concept dat we in dit bericht zullen onderzoeken:
- Waarom Genai-systemen niet op dezelfde manier kunnen worden getest als traditionele software of zelfs klassieke machine learning (ML)
- Waarom beoordelingen essentieel zijn om de kwaliteit van uw AI-systeem te begrijpen en niet optioneel (tenzij u van verrassingen houdt)
- Verschillende soorten beoordelingen en technieken om ze in de praktijk toe te passen
Of u nu een productmanager, een engineer of iemand bent die met AI werkt of erin geïnteresseerd is, ik hoop dat dit bericht u helpt om kritisch na te denken over de kwaliteit van AI-systemen (en waarom evaluaties essentieel zijn om die kwaliteit te bereiken!).
Generatieve AI kan niet worden getest zoals traditionele software, of zelfs zoals klassiek machinaal leren.
Bij traditionele softwareontwikkelingSystemen volgen een deterministische logica: Als X gebeurt, dan zal Y gebeuren. - altijd. Tenzij er iets misgaat met uw platform of u een bug in uw code introduceert... daarom voegen wij tests, monitoring en waarschuwingen toe. Unittests worden gebruikt om kleine codeblokken te valideren, integratietests om te controleren of componenten goed samenwerken en monitoring om te detecteren of er iets mis is in de productie. Traditioneel softwaretesten is te vergelijken met het controleren van de werking van een rekenmachine. Je voert 2 + 2 in en verwacht 4. Duidelijk en onvermijdelijk, waar of onwaar.
Machine learning en kunstmatige intelligentie introduceren echter indeterminisme en waarschijnlijkheid. In plaats van het expliciet specificeren van gedrag door middel van regels, trainen we modellen om patronen uit data te leren. Als bij AI X gebeurt, is de uitkomst niet langer een hard gecodeerde Y, maar een voorspelling met een bepaalde mate van waarschijnlijkheid, gebaseerd op wat het model tijdens de training heeft geleerd.. Dit kan heel krachtig zijn, maar het introduceert ook onzekerheid: identieke invoer kan in de loop van de tijd verschillende uitvoerresultaten opleveren, aannemelijke uitvoerresultaten kunnen in werkelijkheid onjuist zijn en er kan onverwacht gedrag ontstaan in zeldzame scenario's...
Hierdoor zijn traditionele testmethoden onvoldoende en soms zelfs onuitvoerbaar. Het voorbeeld met de rekenmachine komt dicht in de buurt van een manier om de prestaties van een student op een open examen te beoordelen. Is het gegeven antwoord op elke vraag, en op de vele mogelijke manieren om de vraag te beantwoorden, correct? Ligt het kennisniveau boven het niveau dat de student zou moeten hebben? Heeft de student alles verzonnen, maar klinkt het allemaal heel overtuigend? Net als de antwoorden op een examen, AI-systemen kunnen worden geëvalueerd, maar ze hebben een algemenere en flexibelere manier nodig om zich aan te passen aan verschillende invoer, contexten en use cases. (of soorten tests).
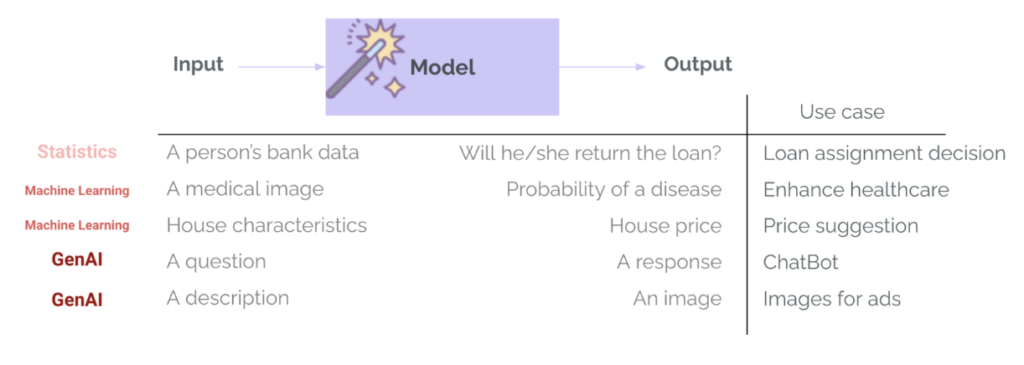
In machine learning Traditioneel (ML) zijn evaluaties al een vast onderdeel van de projectlevenscyclus.. Het trainen van een model voor een specifieke taak, zoals het goedkeuren van leningen of het detecteren van ziekten, omvat altijd een evaluatiestap, waarbij gebruik wordt gemaakt van statistieken zoals precisie, recall, RMSE, MAE... Hiermee wordt gemeten hoe goed het model presteert, worden verschillende modelopties vergeleken en wordt bepaald of het model goed genoeg is om te worden geïmplementeerd. In GenAI is dit doorgaans anders: teams gebruiken modellen die al zijn getraind en die al algemene evaluaties hebben doorstaan, zowel intern door de modelleverancier als in openbare benchmarks. Deze modellen zijn erg goed in algemene taken, zoals het beantwoorden van vragen of het opstellen van e-mails. Er bestaat dan ook het risico dat we ze te veel vertrouwen voor ons specifieke gebruiksscenario. Het is echter belangrijk om de vraag te stellen: “Is dit geweldige sjabloon goed genoeg voor mijn gebruiksdoel?“Dit is waar de evaluatie om de hoek komt kijken.” - Om te evalueren of voorspellingen of generaties geschikt zijn voor een specifiek gebruiksscenario, context, invoer en gebruikers.

Er is nog een groot verschil tussen ML en GenAI: de variëteit en complexiteit van de output van het model. We retourneren geen categorieën en waarschijnlijkheden meer (zoals de waarschijnlijkheid dat een klant een lening terugbetaalt) of getallen (zoals de verwachte prijs van een woning op basis van de kenmerken ervan). GenAI-systemen kunnen veel verschillende soorten uitvoer retourneren, met verschillende lengtes, tonen, inhoud en formaten. Deze modellen hebben ook geen zeer gestructureerde en specifieke invoer meer nodig, maar accepteren doorgaans vrijwel elk type invoer: tekst, afbeeldingen of zelfs audio of video. Het wordt dan een stuk moeilijker om te evalueren.
Waarom evaluaties noodzakelijk zijn en niet optioneel (tenzij u onaangename verrassingen prefereert)
Met evaluaties kunt u meten of uw AI-systeem daadwerkelijk werkt zoals u dat wilt. Je wilt hetof het systeem klaar is voor gebruik en, zo ja, of het blijft presteren zoals verwacht. Hieronder vindt u een analyse van het belang van evaluaties:
- Kwaliteitsbeoordeling: Evaluaties bieden een gestructureerde manier om inzicht te krijgen in de kwaliteit van uw AI-voorspellingen of -uitkomsten en hoe deze in het algehele systeem en de use case worden geïntegreerd. Zijn de antwoorden accuraat? Bruikbaar? Samenhangend? Verwant?
- Kwantificeer fouten: Beoordelingen helpen bij het bepalen van het percentage, het type en de omvang van fouten. Hoe vaak komen fouten voor? Welke soorten fouten komen het vaakst voor (bijvoorbeeld fout-positieve resultaten, hallucinaties, opmaakfouten)?
- Risicobeperking: Hiermee kunt u schadelijk of bevooroordeeld gedrag detecteren en voorkomen voordat het gebruikers bereikt. Zo beschermt u uw bedrijf tegen reputatierisico's, ethische kwesties en mogelijke regelgevingsproblemen.
Generatieve AI, met vrije input-outputrelaties en het genereren van langere teksten, maakt beoordelingen relevanter en complexer. Als dingen fout gaan, kunnen ze heel erg fout gaan. We hebben allemaal de krantenkoppen gezien over chatbots die gevaarlijk advies geven, modellen die bevooroordeelde content genereren en AI-tools die valse feiten hallucineren.
"AI zal nooit perfect zijn, maar door evaluaties te gebruiken kunt u het risico op schaamte verkleinen. Dit kan u geld, geloofwaardigheid of een viraal moment op Twitter kosten."
Hoe definieer je een AI-evaluatiestrategie?

Hoe bepalen wij onze AI-beoordelingen? Er bestaat geen universele beoordelingsmethode. Evaluaties zijn afhankelijk van het specifieke gebruiksscenario en moeten aansluiten op de specifieke doelen van uw AI-toepassing. Als u bijvoorbeeld een zoekmachine bouwt, vindt u het wellicht belangrijk hoe relevant de resultaten zijn. Als het een chatbot is, hecht u mogelijk waarde aan behulpzaamheid en veiligheid. Als het vertrouwelijk is, hecht u waarschijnlijk waarde aan nauwkeurigheid en precisie. Bij systemen die uit meerdere stappen bestaan (zoals een AI-systeem dat een zoekopdracht uitvoert, de resultaten prioriteert en vervolgens een antwoord genereert), is het vaak nodig om elke stap te evalueren. Het idee hierbij is om te meten of elke stap bijdraagt aan het behalen van de algehele succesmaatstaf (en op basis daarvan te bepalen waar iteraties en verbeteringen op gericht moeten worden).
Veelvoorkomende beoordelingsgebieden zijn:
- Correctheid en hallucinaties: Zijn de uitkomsten realistisch nauwkeurig? Genereert het systeem onjuiste informatie of hallucinaties?
- Relevantie: Is de inhoud consistent met de gebruikersvraag of de geboden context?
- veiligheid, vooringenomenheid en toxiciteit
- Formaat: Heeft de uitvoer het verwachte formaat (bijv. JSON, geldige functieaanroep)?
- Veiligheid, vertekening en toxiciteit: Genereert het systeem schadelijke, bevooroordeelde of giftige inhoud?
Taakspecifieke statistieken. Zo worden bij classificatietaken bijvoorbeeld meetgegevens als nauwkeurigheid en precisie gebruikt, bij samenvattingstaken ROUGE of BLEU en bij taken voor het genereren van regex-code en het verifiëren van de foutloze uitvoering.
Hoe worden beoordelingen eigenlijk berekend?
Zodra u hebt bepaald wat u wilt meten, is de volgende stap het ontwerpen van uw testcases. Dit is een reeks voorbeelden (hoe meer hoe beter, maar houd altijd rekening met waarde en kosten) waarbij u het volgende hebt:
- Invoervoorbeeld:Een realistische introductie van uw systeem zodra het in productie gaat.
- Verwachte output (Indien van toepassing): Belangrijk feit of voorbeeld van gewenste uitkomsten.
- Evaluatiemethode: Registratiemechanisme voor het evalueren van het resultaat.
- Resultaat of succes/mislukking: Een berekende metriek die uw testcase evalueert.
Afhankelijk van uw behoeften, tijd en budget zijn er verschillende evaluatietechnieken die u kunt gebruiken:
- Hulpmiddelen voor statistische registratie zoals: BLEU, ROUGE en METEOR, of cosinus-gelijkenismaat tussen inbeddingen – handig voor het vergelijken van gegenereerde tekst met referentie-uitvoer.
- Traditionele machine learning-metrieken zoals Nauwkeurigheid, recall en AUC – het beste voor classificatie met gelabelde gegevens.
- Groot taalmodel als rechter (LLM-als-rechter) Gebruik een groot taalmodel om de uitvoer te evalueren (bijvoorbeeld: "Is dit antwoord juist en nuttig?“). Vooral nuttig wanneer niet-geclassificeerde gegevens niet beschikbaar zijn of bij het evalueren van een open construct.
Codegebaseerde beoordelingen Gebruik reguliere expressies, logische regels of testcase-implementatie om formaten te valideren.
het komt neer op
Laten we alles nog eens samenvatten aan de hand van een concreet voorbeeld. Stel je voor dat je een sentimentanalysesysteem bouwt waarmee je klantenserviceteam binnenkomende e-mails kan prioriteren.
Het doel is om ervoor te zorgen dat er sneller wordt gereageerd op de meest urgente of negatieve berichten. Zo wordt frustratie verminderd, de tevredenheid vergroot en het klantverloop verlaagd. Dit is een relatief eenvoudig gebruiksvoorbeeld, maar zelfs in een systeem als dit, met beperkte output, is kwaliteit van belang: slechte voorspellingen kunnen ertoe leiden dat e-mails willekeurig worden geprioriteerd. Dit betekent dat uw team tijd verspilt met een systeem dat geld kost.
Hoe weet u zeker dat uw oplossing zo goed werkt als u wilt? Je bent aan het evalueren. Hier volgen enkele voorbeelden van zaken die relevant kunnen zijn om te evalueren in dit specifieke gebruiksscenario:
- Formaatvalidatie: Worden de uitkomsten van een LLM-aanroep (Large Language Model) om e-mailsentiment te voorspellen, in de verwachte JSON-indeling geretourneerd? Dit kan worden geëvalueerd via codegebaseerde controles: regex, schemavalidatie, enz.
- Nauwkeurigheid van sentimentclassificatie: Classificeert het systeem sentimenten correct in verschillende teksten – kort, lang en meertalig? Dit kan worden beoordeeld aan de hand van gegevens die zijn gelabeld met behulp van traditionele machine learning-metrieken (ML-metrieken). Als labels niet beschikbaar zijn, kan een groot taalmodel (LLM) als beoordelingsmethode worden gebruikt.
Zodra de oplossing live is, wilt u ook de statistieken opnemen die het meest relevant zijn voor de uiteindelijke impact van uw oplossing.:
- Effectiviteit van prioritering: Worden supportmedewerkers daadwerkelijk doorverwezen naar de belangrijkste e-mails? Is de prioritering afgestemd op de gewenste impact op de business?
- Eindresultaat voor het bedrijf: Zorgt dit systeem er op termijn voor dat de reactietijden worden verkort, het klantverloop wordt verminderd en de klanttevredenheid wordt verbeterd?
Evaluaties zijn essentieel om ervoor te zorgen dat AI-systemen nuttig, veilig, waardevol en klaar voor productiegebruik zijn. Dus of u nu met een eenvoudige classificator of een open chatbot werkt, neem de tijd om te definiëren wat 'goed genoeg' (minimale levensvatbare kwaliteit) inhoudt - en bouw hieromheen beoordelingen om dit te meten!
de recensent
[1] Uw AI-product heeft evaluaties nodigHamel Husain
[2] LLM-evaluatiemetrieken: de ultieme LLM-evaluatiegids, Confident AI
[3] AI-agenten evalueren, deeplearning.ai + Arize
Reacties zijn gesloten.