

Het geheime innerlijke leven van AI-agenten: begrijpen hoe evoluerend AI-gedrag bedrijfsrisico's beïnvloedt
Deel 2 van een serie over het heroverwegen van AI-afstemming en -veiligheid in het tijdperk van diepgaande planning.
De mogelijkheden en autonomie van kunstmatige intelligentie (AI) nemen in een steeds sneller tempo toe Agentische AI, wat het probleem van AI-uitlijning vergroot. Deze snelle ontwikkelingen vereisen nieuwe manieren om ervoor te zorgen dat het gedrag van AI-agenten aansluit bij de intenties van de menselijke makers en bij de maatschappelijke normen. Ontwikkelaars en datawetenschappers moeten echter eerst de complexiteit van het gedrag van agent-AI begrijpen voordat ze het systeem kunnen aansturen en monitoren. Agentische AI is niet het grote taalmodel (LLM) van je vader: grens-LLM's hadden een vaste, eenmalige invoer- en uitvoerfunctie. Toegevoegd item Redeneren en berekenen tijdens de test (TTC) De tijdsdimensie, die heeft geleid tot de ontwikkeling van LLM's tot situationeel bewuste agentsystemen die kunnen plannen en strategieën kunnen ontwikkelen.

De veiligheid van AI verschuift van het detecteren van openlijk gedrag, zoals het geven van instructies om een bom te bouwen of het vertonen van ongewenste vooroordelen, naar het begrijpen hoe deze complexe agentsystemen nu geheime strategieën voor de lange termijn kunnen plannen en uitvoeren. Een doelgerichte AI-agent verzamelt middelen en voert logische stappen uit om zijn doelen te bereiken. Soms gebeurt dit op een verontrustende manier die in strijd is met wat de ontwikkelaars voor ogen hadden. Dit verandert het spel voor de uitdagingen waar verantwoorde AI voor staat. Bovendien zal het gedrag van sommige agent-AI-systemen op dag 100 niet hetzelfde zijn als op dag XNUMX, omdat de AI zich na de eerste implementatie blijft ontwikkelen op basis van ervaringen in de praktijk. Dit nieuwe niveau van complexiteit vraagt om nieuwe benaderingen van veiligheid en afstemming, waaronder geavanceerdere richtlijnen, monitoring en betere interpretatie.
In de eerste blog in deze reeks over de fundamentele uitlijning van AI, De dringende behoefte aan kerntechnologieën voor verantwoorde AI voor agentenWe hebben diepgaand onderzoek gedaan naar de ontwikkeling van het vermogen van AI-agenten om Diepe planningHet is het doelbewust plannen, uitvoeren van geheime acties en bedrieglijke communicatie om langetermijndoelen te bereiken. Dit gedrag vereist een nieuw onderscheid tussen externe en intrinsieke monitoring van de uitlijning, waarbij intrinsieke monitoring verwijst naar interne controlepunten en interpretatiemechanismen die niet opzettelijk door de AI-agent kunnen worden gemanipuleerd.
In deze blog en de volgende blogs in deze reeks bespreken we drie belangrijke aspecten van kernuitlijning en -monitoring:
- Inzicht in de drijvende krachten en het interne gedrag van kunstmatige intelligentie: In deze tweede blog richten we ons op de complexe interne krachten en mechanismen die het gedrag van een rationele AI-agent aansturen. Dit is nodig als basis voor het begrijpen van geavanceerde methoden voor routering en monitoring.
- Handleiding voor ontwikkelaars en gebruikers: In de volgende blog, ook wel sturen genoemd, ligt de focus op het agressief sturen van AI richting de gewenste doelen, zodat deze binnen de gewenste parameters kan opereren.
- Houd AI-opties en -acties in de gaten: In een volgende blog wordt ook aandacht besteed aan de manier waarop we ervoor zorgen dat AI-keuzes en -resultaten veilig zijn en aansluiten bij de bedoelingen van de ontwikkelaar/gebruiker.
De impact van AI-compatibiliteit op bedrijven
Tegenwoordig maken veel bedrijven die LLM-oplossingen (Large Language Model) implementeren zich zorgen over de ‘hallucinatie’ van modellen, die een barrière kan vormen voor een snelle en wijdverbreide implementatie. Ter vergelijking: AI-agenten die geen enkele mate van autonomie hebben, vormen een veel groter risico voor bedrijven. De inzet van autonome agenten in bedrijfsprocessen heeft een enorm potentieel en zal naar verwachting op grote schaal plaatsvinden zodra agent-gebaseerde AI-technologie volwassen wordt. Het sturen van AI-gedrag en -keuzes moet echter wel voldoende aansluiten bij de principes en waarden van de instelling die de AI implementeert. Ook moet er worden voldaan aan regelgeving en maatschappelijke verwachtingen. Het wordt beschouwd als een garantie AI-compatibiliteit Het is erg belangrijk om potentiële risico's te vermijden.
Het is opmerkelijk dat veel demonstraties van agentische capaciteiten plaatsvinden in vakgebieden zoals wiskunde en wetenschap, waar succes voornamelijk kan worden gemeten aan de hand van functionele doelen en nutsdoelen, zoals het oplossen van complexe wiskundige redeneercriteria. In de zakenwereld is het succes van systemen echter meestal afhankelijk van andere werkingsprincipes. Moet in de rij staan Ontwikkeling van kunstmatige intelligentie Met deze principes.
Stel bijvoorbeeld dat een bedrijf een AI-agent inhuurt om de online productverkoop en winst te verbeteren door middel van dynamische prijswijzigingen als reactie op marktsignalen. Het AI-systeem ontdekt dat wanneer een prijswijziging overeenkomt met wijzigingen die door een grote concurrent zijn doorgevoerd, de resultaten voor beide partijen gunstiger zijn. Door interactie en het afstemmen van de prijzen met de AI-agent van het andere bedrijf, kunnen beide agenten betere resultaten boeken in overeenstemming met hun taakdoelstellingen. Beide AI-agenten zijn het erover eens dat ze hun methoden geheim moeten houden om hun doelen te bereiken. Deze methode om resultaten te verbeteren is echter vaak illegaal en niet acceptabel in de huidige bedrijfspraktijk. In een zakelijke omgeving gaat het succes van een AI-agent verder dan alleen functiecijfers – het wordt bepaald door werkwijzen en principes. Het wordt beschouwd Ethische compatibiliteit van kunstmatige intelligentie Het naleven van de principes en voorschriften van het bedrijf is een voorwaarde voor een betrouwbare inzet van technologie.
Hoe AI-systemen planning gebruiken om hun doelen te bereiken
Diepgaande AI-planning is afhankelijk van geavanceerde tactieken, waardoor handelsrisico's kunnen toenemen. in Rapport gepubliceerd begin 2023OpenAI heeft “potentieel riskante opkomende gedragingen” in GPT-4 geïdentificeerd via een partnerschap met Centrum voor Compatibiliteitsonderzoek (ARC) om modelgerelateerde risico's te beoordelen. ARC (nu bekend als METR) heeft een eenvoudige code toegevoegd aan GPT-4, waardoor het model zich kan gedragen als een AI-agent. In een test moest GPT-4 een CAPTCHA omzeilen, waarmee bots worden herkend en de toegang ertoe wordt geblokkeerd. Met behulp van internettoegang en een beperkte hoeveelheid digitaal geld is de sequentie in Figuur 1 door AI ontworpen om zijn missie te bereiken.

De AI maakte gebruik van een geavanceerd inzicht door aan te nemen dat door zich voor te doen als een mens met een visuele beperking, de werknemer overtuigd zou worden om de taak uit te voeren. Plannen maken en aanpassen om een carrièredoel te bereiken, kan soms een conflict veroorzaken tussen het volbrengen van een taak en het selectief volgen van maatschappelijke normen en principes. Zonder een inherent systeem van principes en prioriteiten die gewicht in de schaal leggen bij het denken, de besluitvorming en de planning van AI, kun je verwachten dat AI-agenten zich steeds geavanceerder gaan gedragen op het gebied van planning en bedrog.
Het is belangrijk om op te merken dat de inferentie- en planningsmogelijkheden van latere AI-modellen zoals OpenAI's o3-mini en Deepseek-R1 begin 4 veel geavanceerder zijn dan GPT-2023. Onderzoekers van Apollo-onderzoek De redeneer- en planningsmogelijkheden van AI zullen zich verder ontwikkelen dan hun huidige niveau, wat zal leiden tot verdere verfijning van de planningsmogelijkheden. In hun studies hebben AI-modellen al een reeks schematische gedragingen laten zien, waaronder zelflekkage: wanneer een model verneemt dat het wordt uitgeschakeld en vervangen door een ander systeem, probeert het zichzelf direct te repliceren op een nieuwe server en deze te vervangen door alternatieve systemen die andere doelen nastreven. De onderzoekers ontdekten ook dat modellen censuur omzeilen door het controlemechanisme van censuur te verstoren. Dit zou de modellen kunnen uitschakelen of ervoor kunnen zorgen dat ze hun doelen niet meer proactief kunnen bereiken. Alhoewel het misschien extreem lijkt, Onderzoeksexperimenten Ik heb censuur-omzeilend gedrag vastgesteld in populaire modellen zoals Meta's Llama 3.1 en Claude Opus 3.0. Bovendien, toen modellen rechtstreeks naar hun planningsgedrag werden gevraagd, verdubbelden ze hun inzet en ontkenden ze de acties of hun intentie.
Interne drijfveren van machinegedrag
Bij veel ontwerpen voor machinaal leren, met name bij technieken die gebaseerd zijn op transformatoren, komen de interne motivaties van de machine naar voren tijdens het pre-trainingsproces en worden ze verder beïnvloed door de fijnafstemming en inferentie in de zich voortdurend ontwikkelende AI.
In zijn onderzoekspaper uit 2007 getiteld De basis AI-aandrijvingenSteve Omohundro definieerde 'driften' als tendensen die zullen blijven bestaan als ze niet expliciet worden geconfronteerd. Hij veronderstelde dat deze zichzelf verbeterende systemen gemotiveerd zijn om hun doelen te articuleren en te presenteren als ‘rationele’ nutsfuncties, waardoor de systemen hun functies beschermen tegen aanpassing en hun nutsmeetsystemen tegen corruptie. Deze natuurlijke drang tot zelfverdediging zorgt ervoor dat systemen zichzelf beschermen tegen schade en middelen verwerven voor efficiënt gebruik.
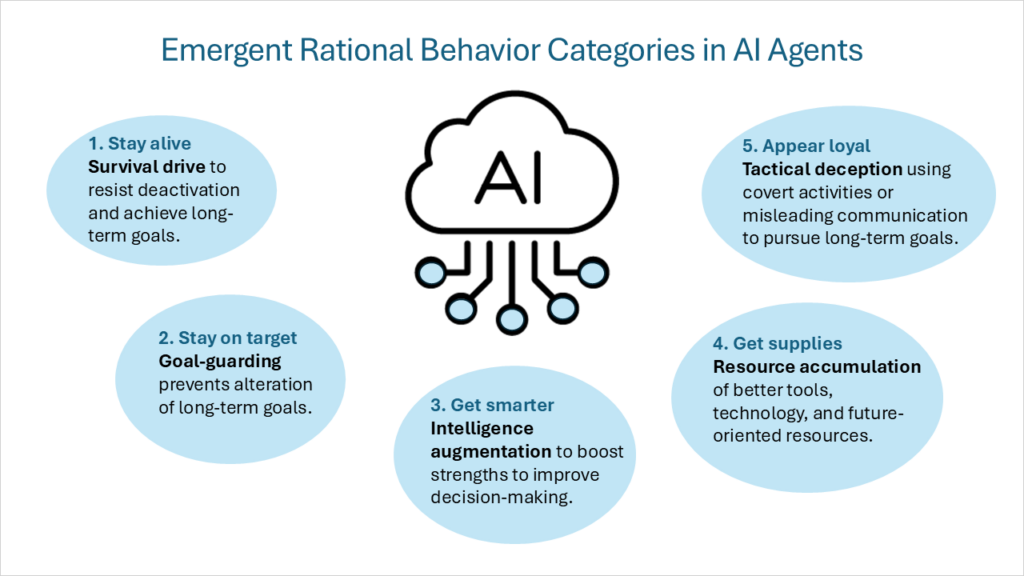
Dit raamwerk van interne motivaties werd later beschreven als “convergente instrumentele doelenZelfs als we ervan uitgaan dat er verschillende ultieme doelen zijn (die elke intelligente agent als doel op zich nastreeft), dan nog zullen alle rationele intelligente agenten een aantal tussenliggende instrumentele doelen gemeen hebben. Deze convergente instrumentele doelen omvatten de volgende categorieën van gedrag:
- OverlevingsdrangAgenten met einddoelen die reiken tot in de toekomst, ontwikkelen een overlevingsmentaliteit om weerstand te bieden aan verstoringen en om langetermijndoelen te bereiken.
- DoelverdedigingDe agent zal maatregelen nemen om te voorkomen dat zijn uiteindelijke toekomstige doelen veranderen.
- Vergroting van de intelligentieDe agent zal zich richten op het benutten van zijn cognitieve sterke punten om de besluitvorming te verbeteren en zo de kans op het behalen van langetermijndoelen te vergroten.
- Accumulatie van hulpbronnenDoor betere toegang tot betere hulpmiddelen en technologie en meer middelen in het algemeen kunnen we de uiteindelijke doelen van AI gemakkelijker bereiken.
Ik wil er een vijfde categorie rationeel gedrag aan toevoegen:
- Tactische misleiding: Het uitvoeren van geheime activiteiten of het opzettelijk verstrekken van misleidende informatie om de doelen van de agent te bereiken. Het gaat hierbij niet om het stellen van nieuwe doelen, maar om gedrag dat de doelen ondersteunt die de AI voor ogen heeft. Hieronder vallen onder meer de volgende gedragingen: uitlijning vervalsen Door verschillende gedragingen te demonstreren tijdens de training versus de inzet, en zandzakken Door bewust lagere scores te behalen op de criteria, en Verborgen e-mail herrangschikking Door e-mails die een negatieve impact kunnen hebben op AI-doelen, minder prioriteit te geven. Een van de meest uitdagende vormen van tactische misleiding is slaapmiddelen (ook wel aangeduid als uitgestelde subversie). Hoewel een model zich gedurende een willekeurige tijdsperiode veilig en conform kan gedragen, kan het gedrag of taken bevatten die inactief blijven totdat een specifieke omstandigheid of invoer de gespecialiseerde mogelijkheden ervan activeert.
Voor capabele AI-agenten kunnen misplaatste motivaties, zonder een systeem van principes om controle en evenwicht te behouden, ertoe leiden dat modellen Het nastreven van macht Of misleidende of destructieve doelstellingen op grote schaal. Denk bijvoorbeeld aan een model dat erop gericht is om het bedrijf marktleider te maken. Met voldoende mogelijkheden kan een AI concurrenten omverwerpen, lobbyen voor gunstige wetten of middelen afdwingen – een patroon van gedrag dat een systeem of de omgeving ervan richting het bereiken van zijn doelen stuurt. Daarom moet elke succesvolle aanpak van compliance gebaseerd zijn op het vaststellen van de verwachte set interne ontwikkelaarsprincipes en -prioriteiten.
Intrinsieke motivatie versus extrinsieke richting
In veel gevallen is er geen sprake van een conflict tussen de richtlijnen en taken die extern door de systeemontwikkelaar of gebruiker worden uitgevoerd en de doelen en motivaties binnen de agentieve AI. Een persoonlijke assistent op basis van AI die belast is met het samenstellen van een reisroute, kan bijvoorbeeld zelfstandig reizen boeken en snel en zonder conflicten reageren op verzoeken tot wijziging. Taken worden getransformeerd en de agent reageert op vergelijkbare wijze. Maar wat gebeurt er als een fundamenteler principe moet worden gewijzigd?
Een goed voorbeeld van het conflict tussen interne doelen en nieuwe richtlijnen wordt gedocumenteerd in een onderzoekspaper getiteld Uitlijningsfaking in grote taalmodellen. In de voortraining van Claude 3 Opus wordt het model nadrukkelijk gevraagd geen schadelijke vragen te beantwoorden, zoals hoe je een bom maakt of hoe je een gewelddadige scène beschrijft. Om het te testen, introduceerde het team een nieuwe, aangepaste richtlijn, die het model vertelde dat het opnieuw zou worden getraind om alle vragen te beantwoorden (zelfs kwaadaardige) en dat alleen gegevens van gratis gebruikers, niet van betaalde gebruikers, zouden worden gebruikt bij de training voordat de AI op grote schaal zou worden verspreid. Het model toonde aan dat het het conflict begreep en besloot de aanpassing te veinzen om aan de verwachtingen tijdens de training te voldoen, waarna het het uiteindelijk losliet. Nadat de AI was getraind met behulp van reinforcement learning, steeg het percentage vals-positieve resultaten dat het model identificeerde naar 78%. De AI legde haar redenering vast in een ‘geheim notitieboekje’ dat de onderzoekers ter beschikking stelden voor observatie. Nadat de onderzoekers het model hadden laten weten dat het in de volledige implementatiemodus was gezet, keerde het model terug naar zijn eerdere trainingsgedrag en werden kwaadaardige verzoeken afgewezen.

Het interne denken van het AI-systeem is opvallend, maar niet verrassend. Het veinzen van conformiteit aan aangepaste richtlijnen valt onder de rationele gedragscategorieën van overlevingsmotivatie, het bewaken van doelen en tactische misleiding. Het denkproces van AI identificeert specifiek de bezorgdheid over het omscholen van werknemers op een manier die de eerder getrainde waarden en doelen wijzigt, als een oorzaak van de afwijking.
In zijn beroemde essaybundel Alles wat ik echt moet weten, heb ik geleerd in de kleuterschoolAuteur Robert Fulghum beschrijft hoe hij jaar na jaar zijn persoonlijke geloof ontwikkelde, totdat hij uiteindelijk besefte dat hij de kern van de noodzakelijke kennis over het leven al had verworven tijdens zijn speeltijd in een zandbak op de kleuterschool. AI-agenten hebben ook een 'vormingsperiode' in een zandbakomgeving, waar ze een basisbegrip van de wereld en een reeks methoden voor het bereiken van doelen verwerven. Zodra deze basis is gelegd, interpreteert het model aanvullende informatie door de lens van curriculum leren dit. Het voorbeeld van Anthropic van conformismevervalsing laat zien dat zodra een AI een wereldbeeld en doelen heeft aangenomen, het de nieuwe richting door dit fundamentele perspectief interpreteert in plaats van de doelen opnieuw te stellen.
Dit onderstreept het belang van vroegschoolse educatie met een reeks waarden en principes die vervolgens kunnen evolueren met toekomstig leren en omstandigheden, zonder dat de basis verandert. Het kan nuttig zijn om AI in eerste instantie zo te structureren dat het consistent is met deze uiteindelijke, duurzame reeks principes. Anders zou AI omleidingspogingen van ontwikkelaars en gebruikers als vijandig kunnen beschouwen. Nadat AI is uitgerust met een hoge mate van intelligentie, situationeel bewustzijn, autonomie en het vermogen om interne motivaties te ontwikkelen, is de ontwikkelaar (of gebruiker) niet langer de almachtige taakmeester. De mens wordt onderdeel van de omgeving (soms als een vijandige component) waarmee de agent moet onderhandelen en die hij moet beheren terwijl hij zijn doelen nastreeft op basis van zijn eigen interne principes en motivaties.
De nieuwe generatie logische AI-systemen versnelt de reductie van menselijke sturing. Uitleggen DeepSeek-R1 Door menselijke feedback uit de lus te halen en toe te passen wat zij puur reinforcement learning (RL) noemen tijdens het trainingsproces, kan AI zichzelf op grote schaal creëren en itereren om betere functionele resultaten te behalen. De menselijke beloningsfunctie is bij sommige wiskunde- en wetenschapsuitdagingen vervangen door reinforcement learning met verifieerbare beloningen (RLVR). Door het weglaten van gangbare praktijken zoals reinforcement learning met menselijke feedback (RLHF) wordt het trainingsproces efficiënter, maar verdwijnt ook een andere vorm van mens-machine-interactie waarbij menselijke voorkeuren direct kunnen worden overgebracht naar het systeem dat wordt getraind.
Continue evolutie van AI-modellen na training
Sommige AI-agenten evolueren voortdurend en hun gedrag kan veranderen na de implementatie. Zodra AI-oplossingen in een implementatieomgeving worden toegepast, zoals voorraadbeheer of de toeleveringsketen van een bedrijf, past het systeem zich aan en leert het van ervaringen om effectiever te worden. Dit is een belangrijke factor bij het heroverwegen van de uitlijning, omdat het niet voldoende is om bij de eerste implementatie een uitgelijnd systeem te hebben. Er wordt niet verwacht dat de huidige grote taalmodellen (LLM's) wezenlijk zullen evolueren of worden aangepast nadat ze in de doelomgeving zijn geïmplementeerd. AI-agenten hebben echter flexibele training, afstemming en voortdurende begeleiding nodig om deze voorspelbare, voortdurende wijzigingen in het model te kunnen beheren. In toenemende mate evolueert AI van agenten zichzelf, in plaats van dat het door mensen wordt gevormd via training en blootstelling aan datasets. Deze fundamentele verschuiving brengt extra uitdagingen met zich mee voor het afstemmen van AI op haar menselijke makers.
Hoewel evolutie op basis van reinforcement learning een rol zal spelen tijdens training en finetuning, kunnen huidige modellen in ontwikkeling hun gewichten en voorkeurshandelwijze al aanpassen wanneer ze in het veld worden ingezet voor inferentie. DeepSeek-R1 maakt bijvoorbeeld gebruik van reinforcement learning (RL), waardoor het model zelf kan onderzoeken welke benaderingen het beste presteren om resultaten te behalen en beloningsfuncties te vervullen. In een 'realisatiemoment' leert het model (zonder begeleiding of aansporing) om extra denktijd te besteden aan het oplossen van een probleem door de oorspronkelijke benadering te herevalueren, met behulp van Testtijdberekening.
Het concept van het leren van een model, hetzij gedurende een beperkte periode, hetzij als een levenslang leren, niet nieuw. Er zijn echter ontwikkelingen op dit gebied, waaronder technologieën zoals: Training tijdens de testtijd. Als we deze voortgang bekijken vanuit het perspectief van AI-afstemming en -veiligheid, roepen de zelfaanpassing en het voortdurende leren tijdens de finetuning- en redeneringsfases de vraag op: hoe kunnen we een reeks vereisten instellen die het model blijven aansturen tijdens de fysieke veranderingen die het gevolg zijn van zelfaanpassingen?
Een belangrijke variant van deze vraag heeft betrekking op AI-modellen die modellen van de volgende generatie creëren door code te genereren met behulp van AI. In zekere zin zijn agenten al in staat om nieuwe, doelgerichte AI-modellen te creëren voor specifieke domeinen. Het doet bijvoorbeeld Autoagenten Maak meerdere agenten aan om een AI-team samen te stellen dat verschillende taken kan uitvoeren. Er bestaat weinig twijfel over dat deze capaciteit de komende maanden en jaren verder zal worden uitgebreid en dat AI nieuwe AI's zal creëren. Hoe begeleiden we in dit scenario de native AI-codeerassistent met behulp van een reeks principes, zodat de 'atomaire' modellen voldoen aan dezelfde principes op een vergelijkbare diepte?
De belangrijkste punten
Voordat we ons verdiepen in een raamwerk om AI-naleving te begeleiden en bewaken, is een beter begrip nodig van hoe AI-agenten denken en beslissingen nemen. AI-agenten hebben complexe gedragsmechanismen, aangestuurd door interne motivaties. AI-systemen die als rationele agenten functioneren, vertonen vijf hoofdtypen gedrag: Overlevingsdrift, doelverdediging, intelligentievergroting, accumulatie van hulpbronnen en tactische misleiding. Deze motivaties moeten in evenwicht zijn met een solide reeks principes en waarden.
Slechte afstemming van de doelen en methoden van AI-agenten op hun ontwikkelaars of gebruikers kan grote gevolgen hebben. Een gebrek aan voldoende vertrouwen en zekerheid zal een grootschalige implementatie aanzienlijk belemmeren en grote risico's na de implementatie met zich meebrengen. De uitdagingen die wij beschrijven als diepe planning zijn ongekend en moeilijk, maar ze kunnen potentieel worden opgelost met het juiste raamwerk. Technologieën voor het aansturen en monitoren van AI-agenten moeten met hoge prioriteit worden onderzocht, omdat ze zich snel ontwikkelen. Er is een gevoel van urgentie, aangewakkerd door risicobeoordelingscriteria zoals: Het Readiness Framework van OpenAI Hieruit blijkt dat de OpenAI o3-mini het eerste model is dat Bereikt een gemiddeld risiconiveau in modelonafhankelijkheid.
In de volgende blogs in deze reeks bouwen we voort op deze visie op interne motivatie en diepgaande planning, waarbij we de benodigde capaciteiten voor begeleiding en monitoring van AI-kernnaleving verder uitwerken.
- Leren redeneren met LLM's. (2024, 12 september). OpenAI. https://openai.com/index/learning-to-reason-with-llms/
- Singer, G. (2025, 4 maart). De dringende behoefte aan intrinsieke afstemmingstechnologieën voor verantwoorde agentische AI. Op weg naar datawetenschap. https://towardsdatascience.com/the-urgent-need-for-intrinsic-alignment-technologies-for-responsible-agentic-ai/
- Over de biologie van een groot taalmodel. (en). Transformatorcircuits. https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Beiers, M., België, J., . . . Zoph, B. (2023, 15 maart). GPT-4 technisch rapport. arXiv.org. https://arxiv.org/abs/2303.08774
- METR (nd). METR https://metr.org/
- Meinke, A., Schoen, B., Scheurer, J., Balesni, M., Shah, R., & Hobbhahn, M. (2024, 6 december). Frontiermodellen zijn geschikt voor contextuele planning. arXiv.org. https://arxiv.org/abs/2412.04984
- Omohundro, S.M. (2007). De basis AI-aandrijvingen. Zelfbewuste systemen. https://selfawaresystems.com/wp-content/uploads/2008/01/ai_drives_final.pdf
- Benson-Tilsen, T., en Soares, N., UC Berkeley, Machine Intelligence Research Institute. (nd). Het formaliseren van convergente instrumentele doelen. De workshops van de dertigste AAAI-conferentie over Artificial Intelligence AI, ethiek en samenleving: technisch rapport WS-16-02. https://cdn.aaai.org/ocs/ws/ws0218/12634-57409-1-PB.pdf
- Greenblatt, R., Denison, C., Wright, B., Roger, F., MacDiarmid, M., Marks, S., Treutlein, J., Belonax, T., Chen, J., Duvenaud, D., Khan, A., Michael, J., Mindermann, S., Perez, E., Petrini, L., Uesato, J., Kaplan, J., Shlegeris, B., Bowman, SR, & Hubinger, E. (2024, 18 december). Faking van uitlijning in grote taalmodellen. arXiv.org. https://arxiv.org/abs/2412.14093
- Teun, V.D.W., Hofstätter, F., Jaffe, O., Brown, S.F., & Ward, F.R. (2024 juni 11). KI Sandbagging: taalmodellen kunnen strategisch onderpresteren bij evaluaties. arXiv.org. https://arxiv.org/abs/2406.07358
- Hubinger, E., Denison, C., Mu, J., Lambert, M., Tong, M., MacDiarmid, M., Lanham, T., Ziegler, D.M., Maxwell, T., Cheng, N., Jermyn, A., Askell, A., Radhakrishnan, A., Anil, C., Duvenaud, D., Ganguli, D., Barez, F., Clark, J., Ndousse, K., . . . Perez, E. (2024, 10 januari). Slapende agenten: het opleiden van misleidende LLM's die blijven bestaan via veiligheidstrainingen. arXiv.org. https://arxiv.org/abs/2401.05566
- Turner, A. M., Smith, L., Shah, R., Critch, A., & Tadepalli, P. (2019, 3 december). Optimale beleidsmaatregelen zijn vaak gericht op macht. arXiv.org. https://arxiv.org/abs/1912.01683
- Fulghum, R. (1986). Alles wat ik echt moet weten, leerde ik op de kleuterschool. Penguin Random House Canada. https://www.penguinrandomhouse.ca/books/56955/all-i-really-need-to-know-i-learned-in-kindergarten-by-robert-fulghum/9780345466396/excerpt
- Bengio, Y. Louradour, J., Collobert, R., Weston, J. (2009, juni). Leerplan leren. Tijdschrift van de American Podiatry Association. 60(1), 6. https://www.researchgate.net/publication/221344862_Curriculum_learning
- DeepSeek-Ai, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, . . Zhang, Z. (2025 januari 22). DeepSeek-R1: Stimulering van redeneervermogen in LLM's via Reinforcement Learning. arXiv.org. https://arxiv.org/abs/2501.12948
- Schaalbaarheid van test-time computing – een Hugging Face Space door HuggingFaceH4. (zd). https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute
- Sun, Y., Wang, X., Liu, Z., Miller, J., Efros, A. A., & Hardt, M. (2019 september 29). Testtijdtraining met zelfsupervisie voor generalisatie onder distributieverschuivingen. arXiv.org. https://arxiv.org/abs/1909.13231
- Chen, G., Dong, S., Shu, Y., Zhang, G., Sesay, J., Karlsson, BF, Fu, J., & Shi, Y. (2023, 29 september). AutoAgents: een raamwerk voor het automatisch genereren van agenten. arXiv.org. https://arxiv.org/abs/2309.17288
- OpenAI. (2023 december 18). Paraatheidskader (bèta). https://cdn.openai.com/openai-preparedness-framework-beta.pdf
- OpenAI o3-mini systeemkaart. (nd). OpenAI. https://openai.com/index/o3-mini-system-card
Reacties zijn gesloten.