

Publieksbeoordeling: 27 AI-modellen, ChatGPT op de 8e plaats – dit zijn de modellen die het beter deden
Hoewel de wereld kunstmatige intelligentie (AI) Hoewel het vaak een turbulent gebied lijkt, vinden er achter de schermen verrassend veel analyses, benchmarks en tests plaats. Niet alleen door de bedrijven zelf, maar ook door groepen die zijn opgericht om hun eigen rangschikkingen te bepalen.

Deze groepen testen alles, van het vermogen van een chatbot om wiskundetests te voltooien,
Maak afbeeldingen, of logische verklaringen geven, of zelfs medisch advies geven, of gewoon laten zien hoe emotioneel intelligent ze is.
Tijdens deze verschillende tests tonen de modellen hun sterke en zwakke punten op verschillende gebieden. Bijvoorbeeld, terwijl GPT-5 Hij blinkt uit in wetenschappelijke deductie, maar hij loopt achter op Gemini en Claude als het gaat om zijn vermogen om zich aan te passen aan nieuwe concepten.
Elk van deze tests vertelt ons iets nieuws over AI-modellen en is belangrijk om ons eraan te herinneren welke tools het beste zijn in verschillende scenario's. Maar er ontbreekt vaak één statistiek: welke AI-modellen leveren de beste gebruikerservaring?
Humaine classificatiesysteem
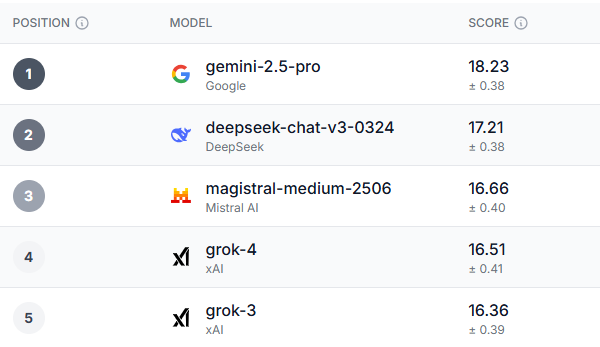
Een in het Verenigd Koninkrijk gevestigd technologiebedrijf genaamd Prolific heeft Een AI-klassement genaamd HumaineIn plaats van het testen van het vermogen van de AI om taken uit te voeren, testte Prolific verschillende gebruikerservaringen met deze modellen.
Door de ervaringen van 21,352 mensen met de tools te evalueren, konden ze niet alleen een algehele winnaar aanwijzen, maar konden ze de resultaten ook uitsplitsen naar leeftijd, locatie (de tests werden uitgevoerd in zowel het Verenigd Koninkrijk als de VS) en politieke overtuigingen.
Dit omvat individuele vermeldingen voor:
- Verenigd Koninkrijk: Leeftijdsgroepen
- Verenigd Koninkrijk: Race
- Verenigd Koninkrijk: Politiek standpunt
- Verenigde Staten: Leeftijdsgroepen
- Verenigde Staten: Ras
- Verenigde Staten: Politiek standpunt
Het team liet elke deelnemer met twee afzonderlijke AI-modellen interacteren om ze met elkaar te vergelijken en vroeg hen feedback te geven over welk model in welke interactie beter presteerde.
Dit resulteerde in een algehele winnaar en een ranglijst voor prestaties, maar ook aparte ranglijsten voor basistaakuitvoering en redeneren, en een winnaar voor communicatie, veerkracht, vertrouwen en ethiek.
Wat laten de resultaten zien?

Na een grondige evaluatie kwam er een duidelijke winnaar naar voren, niet alleen in de algehele prestatiecategorie, maar in de meeste subcategorieën. De Gemini 2.5-Pro blonk uit in bijna elke benchmark die de test onderzocht.
Jongeren van 18 tot 34 jaar in het Verenigd Koninkrijk, Democratische kiezers en mensen boven de 55 in de VS waren het erover eens dat Tweeling 2.5 Pro Het is over het algemeen het beste model. Het enige gebied waarop alle demografische groepen hoger scoorden dan Gemini, was vertrouwen, ethiek en veiligheid, en dat was Grok-3 – een ietwat ironische bevinding gezien de recente veiligheids- en ethische problemen waarmee AI-modellen te maken hebben gehad.
Interessant genoeg zijn de drie modellen die na Gemini naar voren kwamen Deepseek, Magistral Le Chat en GrokHoewel Deepseek eerder dit jaar enorm populair was, is het de laatste tijd van de radar verdwenen. Le Chat daarentegen is een minder populaire chatbot, maar heeft wel een trouwe schare fans.
Dus waar past de wereldberoemde ChatGPT in dit alles? Hij staat onderaan de lijst, op de achtste plaats met het hoogst gewaardeerde GPT-4.1-model. Nog erger is Claude, waar de vier edities op de elfde en twaalfde plaats eindigden in het algemeen klassement.
Wat betekent dit nu allemaal?
Betekent dit dat Gemini de beste AI-chatbot ter wereld is? Betekent dit dat je ChatGPT moet laten vallen…? Nou, niet helemaal.
Deze resultaten weerspiegelen niet noodzakelijkerwijs de prestaties van deze modellen. Wanneer we ze testen met de meeste andere statistieken, zien we meestal ChatGPT, Gemini, Claude en Grok bovenaan staan.
Dit is echter een belangrijke aanvulling op deze tests. Ze helpen ons AI beter te begrijpen vanuit het perspectief van de menselijke ervaring. Zo scoort Le Chat niet hoog op standaard benchmarks, maar wordt het vaak genoemd als een uitstekende keuze qua ervaring en betrouwbaarheid.
Hoewel de prestaties van Anthropic en OpenAI dit niveau in deze testronde niet helemaal haalden, was het wederom een sterke prestatie voor zowel Gemini als Grok. Beide bedrijven behalen vaak hoge scores op standaardbenchmarks, en dat bleven ze ook hier doen.
Reacties zijn gesloten.