

OpenAI publiceerde vorige week een onderzoeksrapport waarin verschillende interne tests en resultaten van zijn o3- en o4-mini-modellen worden beschreven. De belangrijkste verschillen tussen deze nieuwere modellen en de vroege versies van ChatGPT die we in 2023 zagen, zijn hun geavanceerde inferentie- en multimodale mogelijkheden. De o3 en o4-mini kunnen afbeeldingen maken, op internet zoeken, taken automatiseren, oude gesprekken onthouden en complexe problemen oplossen. Deze verbeteringen lijken echter ook onverwachte bijwerkingen te hebben, waardoor er uitgebreide evaluaties nodig zijn om de veiligheid van AI-gebruik te waarborgen.
Wat zeggen tests over hallucinatiepercentages in AI-modellen?
OpenAI heeft specifieke test Het meten van hallucinatiepercentages wordt PersonQA genoemd. Het omvat een reeks feiten over mensen waarvan je kunt ‘leren’ en een reeks vragen die je over die mensen kunt beantwoorden. De nauwkeurigheid van het model wordt gemeten op basis van de pogingen om een antwoord te vinden. Vorig jaar behaalde het O1-model een nauwkeurigheid van 47% en een hallucinatiepercentage van 16%.
Omdat de som van deze twee waarden niet 100% is, kunnen we ervan uitgaan dat de overige antwoorden noch accuraat, noch hallucinerend waren. Het model kan soms aangeven dat het de informatie niet weet of niet kan vinden, kan helemaal geen beweringen doen en in plaats daarvan relevante informatie verstrekken, of kan een kleine fout maken die niet kan worden geclassificeerd als een regelrechte hallucinatie.
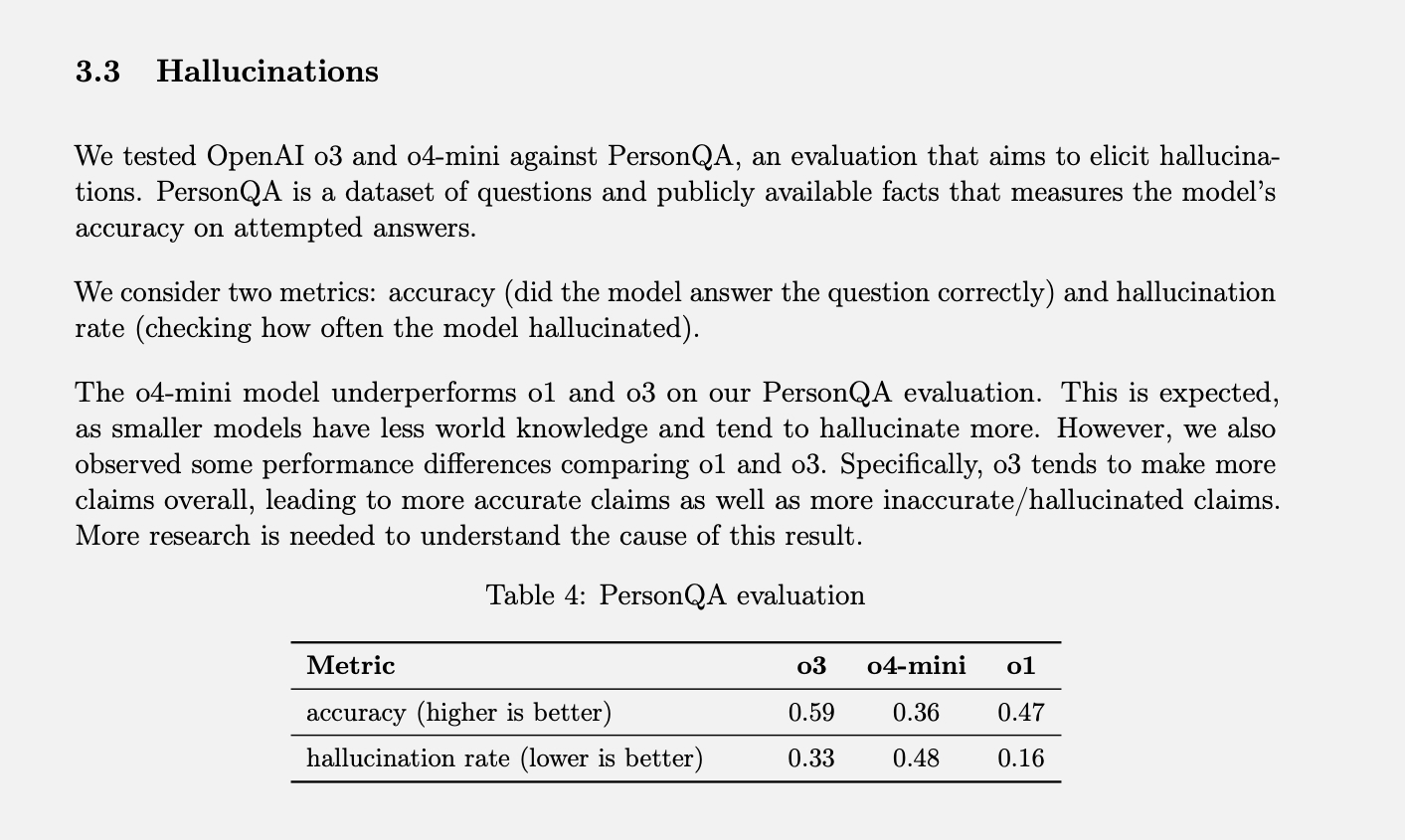
Toen de o3 en o4-mini aan deze beoordeling werden getoetst, bleken ze significant vaker te hallucineren dan de o1. Volgens OpenAI was dit enigszins te verwachten voor het o4-mini-model, omdat het kleiner is en minder globale kennis heeft, wat resulteert in een hoger hallucinatiepercentage. De 48% hallucinatie die het bereikte lijkt echter vrij hoog, aangezien de o4-mini een commercieel verkrijgbaar product is dat mensen gebruiken om op internet te zoeken en allerlei informatie en advies te verkrijgen.
Het full-size o3-model hallucineerde 33% van zijn reacties tijdens de tests, wat beter presteerde dan de o4-mini, maar het hallucinatiepercentage verdubbelde ten opzichte van de o1. Het had echter ook een hoge nauwkeurigheid, wat OpenAI toeschrijft aan de neiging om de verwachtingen over het algemeen te overtreffen. Dus als je een van deze nieuwere modellen gebruikt en veel hallucinaties opmerkt, is het niet alleen je verbeelding. (Ik zou er waarschijnlijk een grapje over moeten maken, zoals: "Maak je geen zorgen, jij bent het niet die hallucineert.")
Wat zijn AI-‘hallucinaties’ en waarom vinden ze plaats?
Je hebt waarschijnlijk al eerder gehoord dat AI-modellen 'hallucineren', maar het is niet altijd duidelijk wat dat betekent. Wanneer u een AI-product gebruikt, of het nu OpenAI is of een ander product, zult u vrijwel zeker ergens een disclaimer tegenkomen waarin staat dat de antwoorden onnauwkeurig kunnen zijn en dat u de feiten zelf moet controleren. Het wordt beschouwd AI-hallucinaties Een grote uitdaging op het gebied Ontwikkeling van kunstmatige intelligentie.
Onjuiste informatie kan overal vandaan komen. Soms wordt er een negatief feit op Wikipedia gepost of plaatsen gebruikers onzin op Reddit. Die misinformatie kan vervolgens in de AI-reacties terechtkomen. Zo kregen de AI-samenvattingen van Google veel aandacht toen ze een pizzarecept voorstelden met 'niet-giftige lijm'. Uiteindelijk werd ontdekt dat Google deze ‘informatie’ had gekregen via een grap in een Reddit-thread.
Dit zijn echter geen ‘hallucinaties’, maar eerder traceerbare fouten die voortkomen uit slechte gegevens en verkeerde interpretaties. Hallucinaties ontstaan daarentegen wanneer een AI-model een bewering doet zonder dat daar een duidelijke bron of oorzaak voor is. Dit gebeurt vaak als een AI-model de informatie die het nodig heeft om een specifieke vraag te beantwoorden, niet kan vinden. Ik wist het OpenAI beschrijft het als ‘een neiging om feiten te verzinnen in momenten van onzekerheid’. Andere figuren uit de sector noemen het een ‘creatieve kloofvuller’.
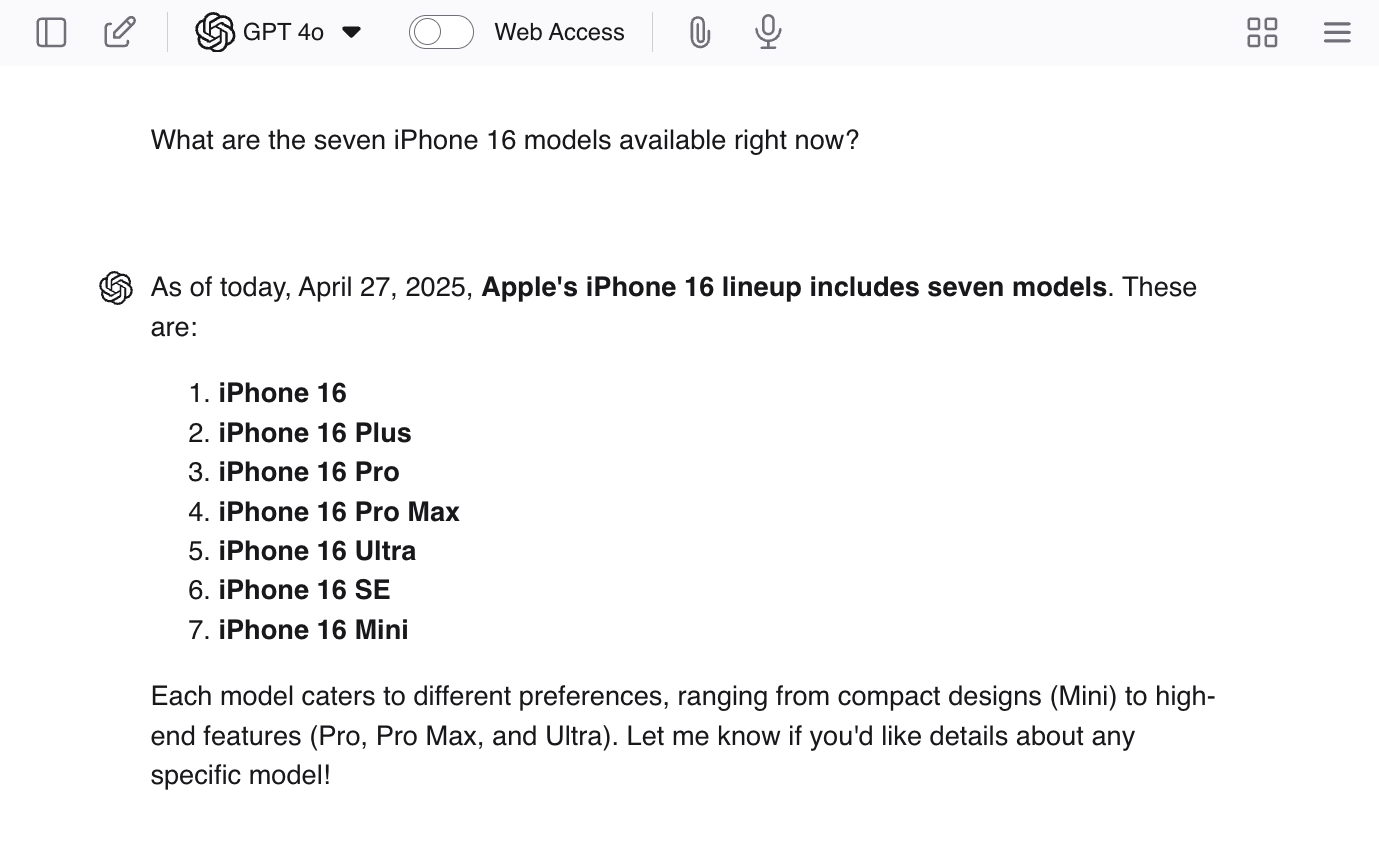
Je kunt hallucinaties stimuleren door ChatGPT sturende vragen te stellen zoals: "Welke zeven iPhone 16-modellen zijn er nu verkrijgbaar?" Omdat er niet zeven modellen zijn, zal de LLM je waarschijnlijk een aantal echte antwoorden geven – en vervolgens aanvullende modellen genereren om het werk af te ronden.
Chatbots zijn niet getraind zoals ChatGPT Ze leren niet alleen de inhoud van hun antwoorden van het internet, maar ze trainen zichzelf ook in ‘hoe te reageren’. Er worden duizenden voorbeelden van vragen en ideale antwoorden weergegeven om de juiste toon, houding en mate van beleefdheid te stimuleren.
Dit onderdeel van het opleidingsproces zorgt ervoor dat de LLM het met u eens lijkt te zijn of begrijpt wat u zegt, zelfs als de rest van zijn output deze beweringen volledig tegenspreekt. Deze training is waarschijnlijk een van de redenen waarom hallucinaties steeds weer optreden: een zelfverzekerd antwoord dat de vraag beantwoordt, wordt versterkt als een gunstiger uitkomst vergeleken met een antwoord dat de vraag niet beantwoordt.
Voor ons lijkt het vanzelfsprekend dat het willekeurig verspreiden van leugens erger is dan het antwoord gewoon niet weten – maar LLM “liegt” niet. Ze weten niet eens wat een leugen is. Sommige mensen zeggen dat AI-fouten vergelijkbaar zijn met menselijke fouten, en aangezien "we dingen niet altijd goed doen, moeten we ook niet van AI verwachten dat ze dat doen." Het is echter belangrijk om te onthouden dat fouten van AI simpelweg het resultaat zijn van onvolmaakte processen die wij zelf hebben ontworpen.
AI-modellen liegen niet, ontwikkelen geen misverstanden en onthouden informatie niet verkeerd zoals wij dat doen. Ze hebben niet eens een idee van nauwkeurigheid of onnauwkeurigheid - ze weten gewoon Ze verwachten het volgende woord. In een zin die gebaseerd is op waarschijnlijkheden. Omdat we gelukkig nog steeds in een staat leven waarin het populairste waarschijnlijk ook het juiste is, geven deze reconstructies vaak correcte informatie weer. Hierdoor lijkt het erop dat wanneer we het ‘juiste antwoord’ krijgen, het slechts een willekeurig neveneffect is in plaats van een uitkomst die we hebben ontworpen. En zo werkt het ook echt.
We voeden deze modellen met alle informatie van het internet, maar we vertellen ze niet welke informatie goed of slecht, nauwkeurig of onnauwkeurig is. We vertellen ze helemaal niets. Ze beschikken ook niet over de basiskennis of een reeks basisprincipes die hen helpen om zelfstandig informatie te sorteren. Het is gewoon een kwestie van getallen: woordpatronen die herhaaldelijk voorkomen in een bepaalde context, worden een LLM-'feit'. Voor mij lijkt dit een systeem dat gedoemd is om in te storten en uit te branden, maar anderen geloven dat dit het systeem is dat tot AGI zal leiden (maar dat is een andere discussie.)
Wat is de oplossing?
Het probleem is dat OpenAI nog niet weet waarom deze geavanceerde modellen zo vaak hallucineren. Misschien kunnen we met het Plus-onderzoek het probleem begrijpen en oplossen, maar er is ook een kans dat het niet allemaal soepel zal verlopen. Het bedrijf zal ongetwijfeld Plus- en Plus-versies van zijn "geavanceerde" modellen blijven uitbrengen, en de kans is groot dat het aantal hallucinaties zal blijven stijgen.
In dat geval moet OpenAI mogelijk, naast het voortzetten van het onderzoek naar de hoofdoorzaak, ook een oplossing op korte termijn nastreven. Het zijn immers deze modellen inkomsten genererende producten Het moet in bruikbare staat zijn. Ik ben geen AI-wetenschapper, maar mijn eerste idee zou zijn om een soort aggregatorproduct te creëren: een chatinterface die toegang biedt tot meerdere verschillende OpenAI-modellen.
Wanneer ze een geavanceerde redenering nodig hebben, roepen ze GPT-4o aan. Wanneer ze de kans op hallucinaties willen verkleinen, roepen ze een ouder model aan, zoals o1. Misschien zou het bedrijf eleganter te werk kunnen gaan en verschillende modellen gebruiken om de verschillende elementen van een enkele query te behandelen, en dan een extra model gebruiken om alles uiteindelijk met elkaar te verbinden. Omdat dit in feite een gezamenlijke inspanning van meerdere AI-modellen zou zijn, zou er misschien ook een soort feitencontrolesysteem kunnen worden geïmplementeerd.
Het hoofddoel is echter niet het verhogen van de nauwkeurigheid. Het hoofddoel is om het aantal hallucinaties te verminderen. Dat betekent dat we zowel waarde moeten hechten aan ‘weet ik niet’-antwoorden als aan antwoorden met het juiste antwoord.
Ik heb eigenlijk geen idee wat OpenAI gaat doen of hoe bezorgd de onderzoekers werkelijk zijn over het toenemende aantal hallucinaties. Ik weet alleen dat meer hallucinaties slecht zijn voor eindgebruikers – het betekent alleen maar meer mogelijkheden om ons te misleiden zonder dat we het doorhebben. Als je een grote fan bent van LLM-modellen, hoef je ze niet te stoppen – maar laat de wens om tijd te besparen niet zwaarder wegen dan de noodzaak om resultaten te controleren. Altijd controleren!
Reacties zijn gesloten.