

Zekerheid verkrijgen in grote taalmodellen (LLM's) met behulp van intelligente besluitvormingscircuits
Onzekerheid is niet nieuw in de technologie: alle moderne systemen overwinnen onzekere invoer- en uitvoerfouten met behulp van wiskundig bewezen regelstructuren.
De belofte van AI-agenten heeft de wereld veroverd. Agenten kunnen met de wereld om hen heen communiceren, artikelen schrijven (maar niet dit artikel), namens u acties uitvoeren en over het algemeen de moeilijkste taken voor u automatiseren, zodat u ze eenvoudig en toegankelijk kunt maken.
Agenten richten zich op de moeilijkste onderdelen van de operatie en lossen problemen snel op. Soms te snel – Als uw agentgebaseerde proces een menselijke tussenpersoon vereist die over de uitkomst beslist, kan de menselijke beoordelingsfase een knelpunt in het proces worden.
Een voorbeeld van een agentgebaseerd proces is het verwerken en classificeren van telefoongesprekken van klanten. Zelfs een agent met een nauwkeurigheid van 99.95% maakt 5 fouten tijdens het beluisteren van 10,000 gesprekken. Ook al weet de agent dit, hij kan het u niet vertellen. Welke 5 van de 10,000 oproepen waren verkeerd geclassificeerd.

De “LLM-als-rechter”-techniek is een techniek waarbij u elke invoer invoert in een ander LLM-proces om te evalueren of de uitvoer van de invoer correct is. Omdat dit echter een ander LLM-proces is, kan dit ook onnauwkeurig zijn. Deze twee waarschijnlijkheidsbewerkingen creëren een verwarringsmatrix met echte positieven, valse negatieven, echte negatieven en valse positieven.
Met andere woorden: een inschrijving die door een LLM-procedure correct is geclassificeerd, kan door de beoordelaar LLM als onjuist worden beoordeeld en vice versa.
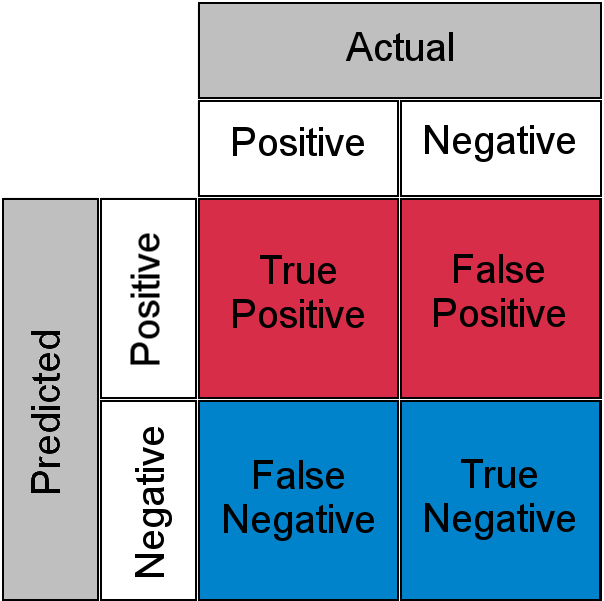
vanwege dit " Het onbekende bekende "Voor een gevoelige taak moet een mens alle 10,000 oproepen beoordelen en begrijpen. We zitten weer met hetzelfde knelpunt.
Hoe kunnen we meer statistische zekerheid inbouwen in onze agentgestuurde processen? In dit bericht bouw ik een systeem waarmee we meer zekerheid krijgen in onze agentgestuurde processen, generaliseer ik dit naar een willekeurig aantal agenten en ontwikkel ik een kostenfunctie om toekomstige investeringen in het systeem te sturen. De code die ik in dit bericht gebruik, is beschikbaar in mijn repository. ai-beslissingscircuits.
AI-besluitvormingscircuits
Het detecteren en corrigeren van fouten zijn geen nieuwe concepten. Foutcorrectie is van cruciaal belang in sectoren zoals digitale en analoge elektronica. Zelfs vooruitgang in quantum computing is afhankelijk van uitbreiding van de mogelijkheden voor foutcorrectie en -detectie. We kunnen inspiratie halen uit deze systemen en iets soortgelijks implementeren met AI-agenten. U kunt bijvoorbeeld: Algoritmen voor kunstmatige intelligentie Geavanceerd gebruik van foutcorrectietechnieken die in communicatiesystemen worden gebruikt.
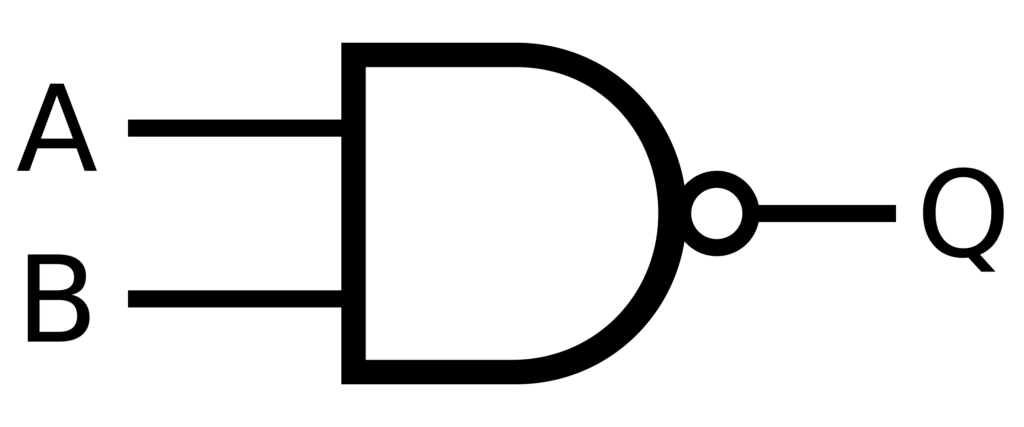
In de Booleaanse logica zijn NAND-poorten de heilige graal van de computertechnologie, omdat ze elke gewenste bewerking kunnen uitvoeren. Het is functioneel compleet, wat betekent dat elke logische bewerking alleen met NAND-poorten kan worden gemaakt. Dit principe kan worden toegepast op AI-systemen om robuuste besluitvormingsstructuren te creëren met ingebouwde foutcorrectie. Dit maakt het mogelijk om: neurale netwerken Betrouwbaarder en beter in staat om onvolledige of onduidelijke gegevens te verwerken.
Van elektronische schakelingen tot intelligente besluitvormingsschakelingen (AI)
Net zoals elektronische schakelingen herhaling en verificatie gebruiken om betrouwbare berekeningen te garanderen, kunnen intelligente besluitvormingsschakelingen (AI) meerdere agenten met verschillende perspectieven gebruiken om tot nauwkeurigere resultaten te komen. Deze schakelingen kunnen worden gebouwd met behulp van principes uit de informatietheorie en de Booleaanse logica:
- Redundante verwerking: Meerdere AI-agenten verwerken onafhankelijk van elkaar dezelfde invoer, vergelijkbaar met de manier waarop moderne CPU's redundante circuits gebruiken om hardwarefouten te detecteren. Dit proces verhoogt de betrouwbaarheid van het AI-systeem.
- Consensusmechanismen: De uitkomsten van beslissingen worden gecombineerd met behulp van stemsystemen of gewogen gemiddelden, vergelijkbaar met meerderheidslogische poorten in fouttolerante elektronica. Deze mechanismen zorgen ervoor dat de uiteindelijke beslissing de consensus onder de agenten weerspiegelt.
- Validatoragenten: Gespecialiseerde AI-auditors controleren de redelijkheid van de output, en werken op een vergelijkbare manier als foutdetectiecodes zoals Pariteitsbits أو cyclische redundantiecontroles (CRC-controles). Deze middelen verkleinen de kans dat u de verkeerde beslissing neemt.
- Human-in-the-Loop-integratie: Strategische menselijke verificatie op belangrijke punten in het besluitvormingsproces, vergelijkbaar met de manier waarop biometrische systemen menselijk toezicht gebruiken als laatste verificatielaag. Zo wordt gegarandeerd dat belangrijke beslissingen door mensen worden beoordeeld.
Wiskundige grondslagen van besluitvormingscircuits in kunstmatige intelligentie
De betrouwbaarheid van deze systemen kan kwantitatief worden bepaald met behulp van de kansrekening.
Ten eerste komt de kans op falen voort uit de waargenomen nauwkeurigheid in de loop van de tijd in een testgegevensset, opgeslagen in een systeem zoals LangSmith.

Voor een nauwkeurigheid van 90% is de kans op falen, p_1، 1–0.9 Het is 0.1 of 10%.

De waarschijnlijkheid dat twee onafhankelijke factoren bij dezelfde invoer falen, is de waarschijnlijkheid dat beide factoren nauwkeurig zijn vermenigvuldigd:
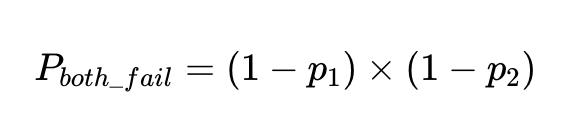
Als we N uitvoeringen met deze clients hebben, is het totale aantal mislukkingen
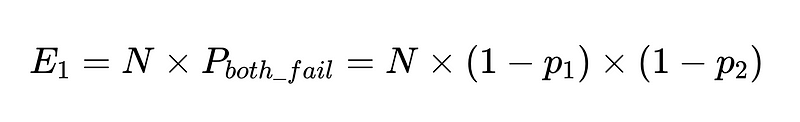
Dus bij 10,000 uitvoeringen tussen twee onafhankelijke werkers met een nauwkeurigheid van 90%, is het verwachte aantal mislukkingen 100.
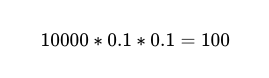
Maar we weten het nog steeds niet. Welke Van die 10,000 telefoontjes zijn er 100 daadwerkelijk mislukt.
We kunnen vier uitbreidingen van dit idee combineren om tot een robuustere oplossing te komen die vertrouwen geeft in elk gegeven antwoord:
- Basisclassificatie (eenvoudige resolutie hierboven)
- Back-up (eenvoudige oplossing hierboven)
- Schemacontrole (bijvoorbeeld resolutie 0.7)

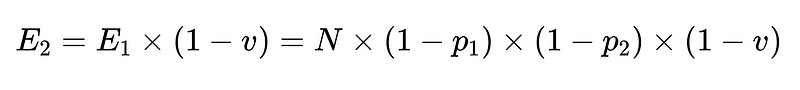
- Ten slotte een negatieve validator (n = nauwkeurigheid 0.6 bijvoorbeeld)
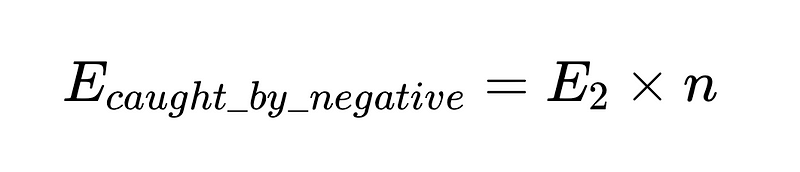
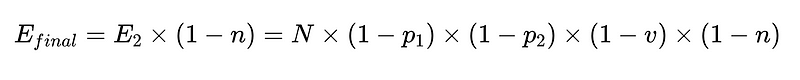
Om dit in code te zetten (Het complete magazijn), kunnen we gebruiken Python basis:
def primary_parser(self, customer_input: str) -> Dict[str, str]:
"""
Primary parser: Direct command with format expectations.
"""
prompt = f"""
Extract the category of the customer service call from the following text as a JSON object with key 'call_type'.
The call type must be one of: {', '.join(self.call_types)}.
If the category cannot be determined, return {{'call_type': null}}.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def backup_parser(self, customer_input: str) -> Dict[str, str]:
"""
Backup parser: Chain of thought approach with formatting instructions.
"""
prompt = f"""
First, identify the main issue or concern in the customer's message.
Then, match it to one of the following categories: {', '.join(self.call_types)}.
Think through each category and determine which one best fits the customer's issue.
Return your answer as a JSON object with key 'call_type'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def negative_checker(self, customer_input: str) -> str:
"""
Negative checker: Determines if the text contains enough information to categorize.
"""
prompt = f"""
Does this customer service call contain enough information to categorize it into one of these types:
{', '.join(self.call_types)}?
Answer only 'yes' or 'no'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
answer = response.content.strip().lower()
if "yes" in answer:
return "yes"
elif "no" in answer:
return "no"
else:
# Default to yes if the answer is unclear
return "yes"
@staticmethod
def validate_call_type(parsed_output: Dict[str, Any]) -> bool:
"""
Schema validator: Checks if the output matches the expected schema.
"""
# Check if output matches expected schema
if not isinstance(parsed_output, dict) or 'call_type' not in parsed_output:
return False
# Verify the extracted call type is in our list of known types or null
call_type = parsed_output['call_type']
return call_type is None or call_type in CALL_TYPESDoor deze bewerkingen te combineren met logica, Boolean Simpel gezegd kunnen we voor elk antwoord een vergelijkbare nauwkeurigheid en vertrouwen krijgen:
def combine_results(
primary_result: Dict[str, str],
backup_result: Dict[str, str],
negative_check: str,
validation_result: bool,
customer_input: str
) -> Dict[str, str]:
"""
Combiner: Combines the results from different strategies.
"""
# If validation failed, use backup
if not validation_result:
if RobustCallClassifier.validate_call_type(backup_result):
return backup_result
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If negative check says no call type can be determined but we extracted one, double-check
if negative_check == 'no' and primary_result['call_type'] is not None:
if backup_result['call_type'] is None:
return {'call_type': None, "confidence": "low", "needs_human": True}
elif backup_result['call_type'] == primary_result['call_type']:
# Both agree despite negative check, so go with it but mark low confidence
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If primary and backup agree, high confidence
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "high"}
# Default: use primary result with medium confidence
if primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {'call_type': None, "confidence": "low", "needs_human": True}
Beslissingslogica: een stapsgewijze uitleg
Stap 1: Wanneer het kwaliteitscontrolesysteem faalt
if not validation_result:Dit betekent: “Als onze kwaliteitscontrole-expert (auditor) de eerste analyse afwijst, vertrouw er dan niet op.” Het systeem probeert dan in plaats daarvan de reserveopinie te gebruiken. Als ook dit niet lukt, wordt de zaak gemarkeerd voor beoordeling door een menselijke specialist. Met deze procedure weet u zeker dat u niet op onjuiste gegevens vertrouwt.
Simpel gezegd: "Als er iets niet klopt aan ons eerste antwoord, laten we dan onze back-upmethode proberen. Als dat nog steeds twijfelachtig is, laten we dan een menselijke expert vragen om in te grijpen." Zo wordt gewaarborgd dat complexe zaken op de juiste wijze worden afgehandeld.
Stap 2: Pak afwijkingen aan
if negative_check == 'no' and primary_result['call_type'] is not None:In deze stap wordt gecontroleerd op een specifiek type discrepantie: "Onze negatieve checker geeft aan dat er geen call-type zou moeten zijn, maar onze fundamentele analist heeft toch een put-type gevonden."
In dergelijke gevallen vertrouwt het systeem op de fallback-analist om het break-even punt te bereiken:
- Als de back-upanalist aangeeft dat er geen oproeptype is, wordt deze doorgestuurd naar de menselijke factor.
- Als de reserve-analist het eens is met de primaire analist, wordt het geaccepteerd, maar met een gemiddelde mate van zekerheid.
- Als de back-upanalist een ander oproeptype heeft ← wordt dit naar het menselijke element verzonden
Het is alsof je zegt: “Als de ene deskundige zegt ‘dit is niet te classificeren’, maar een ander zegt van wel, dan hebben we een beslisser of een menselijke rechter nodig.” Dit mechanisme is nodig om een nauwkeurige classificatie van oproeptypen te garanderen en potentiële fouten te beperken.
Stap 3: Wanneer de experts het eens zijn
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:Wanneer zowel de primaire als de reserve-analist onafhankelijk van elkaar tot dezelfde conclusie komen, markeert het systeem dit als ‘hoog vertrouwen’ – dit is het beste scenario. Deze ideale situatie ontstaat wanneer meerdere analyses eenduidig consistent zijn.
Simpel gezegd: "Als twee verschillende experts, die verschillende methoden gebruiken, onafhankelijk van elkaar tot dezelfde conclusie komen, kunnen we er vrij zeker van zijn dat hun conclusie juist is." Dit vertegenwoordigt de consensus onder experts, wat een sterke indicator is van nauwkeurigheid en betrouwbaarheid.
Stap 4: Standaardverwerking
Als geen van de speciale voorwaarden van toepassing is, gaat het systeem standaard uit van het resultaat van de primaire analist met een ‘gemiddeld’ vertrouwen. Als de hoofdanalist het type oproep niet kan identificeren, markeert hij/zij de zaak ter beoordeling door een gespecialiseerde menselijke analist.
Het belang van deze aanpak bij het verminderen van fouten
Deze logica draagt bij aan het opbouwen van een sterk systeem door:
- Het verminderen van foutpositieve resultatenHet systeem geeft alleen een hoog betrouwbaarheidsniveau als meerdere methoden met elkaar overeenkomen, waardoor het aantal valse alarmen aanzienlijk wordt verminderd.
- Het ontdekken van tegenstrijdighedenWanneer er verschillen zijn tussen verschillende onderdelen van het systeem, leidt dit tot minder vertrouwen of wordt de kwestie doorgestuurd naar menselijke beoordelaars. Zo wordt voorkomen dat mogelijke problemen over het hoofd worden gezien.
- Slimme escalatieMenselijke beoordelaars zien alleen zaken die daadwerkelijk hun expertise vereisen. Hierdoor verloopt het beoordelingsproces efficiënter en wordt de stress op de werkvloer verminderd.
- Trust-aanduidingDe resultaten omvatten het betrouwbaarheidsniveau van het systeem, waardoor daaropvolgende processen resultaten met een hoog betrouwbaarheidsniveau verschillend kunnen behandelen dan resultaten met een gemiddeld betrouwbaarheidsniveau. Dit is essentieel voor het nemen van weloverwogen beslissingen.
Deze aanpak is vergelijkbaar met de manier waarop elektronica redundante circuits en stemmechanismen gebruikt om te voorkomen dat fouten tot systeemstoringen leiden. In AI-systemen kan dit soort doordachte integratielogica de foutpercentages aanzienlijk verminderen en worden menselijke beoordelaars alleen efficiënt ingezet waar zij de meeste waarde toevoegen. Hiermee wordt ervoor gezorgd dat bronnen optimaal worden benut en fouten worden verminderd. Het systeem is daardoor betrouwbaarder en nauwkeuriger.
Voorbeeld
In 2015 publiceerde de Waterafdeling van de stad Philadelphia Statistieken over klantgesprekken per categorie. Het begrijpen van telefoongesprekken van klanten is een veelvoorkomend proces waar agenten mee te maken hebben. In plaats van dat een mens naar elk telefoontje van een klant luistert, kan een agent veel sneller naar het gesprek luisteren, informatie eruit halen en het gesprek categoriseren voor verdere gegevensanalyse. Voor het waterbeheer is dit van belang, want hoe eerder ernstige problemen worden geïdentificeerd, hoe sneller deze problemen kunnen worden opgelost.
Wij kunnen een ervaring creëren. Ik heb een groot taalmodel (LLM) gebruikt om nep-transcripties te genereren van de telefoongesprekken in kwestie door te vragen: "Gegeven de volgende klasse, genereer een korte versie van dat telefoongesprek: Hieronder vindt u enkele voorbeelden met het volledige bestand beschikbaar. hier:
{
"calls": [
{
"id": 5,
"type": "ABATEMENT",
"customer_input": "I need to report an abandoned property that has a major leak. Water is pouring out and flooding the sidewalk."
},
{
"id": 7,
"type": "AMR (METERING)",
"customer_input": "Can someone check my water meter? The digital display is completely blank and I can't read it."
},
{
"id": 15,
"type": "BTR/O (BAD TASTE & ODOR)",
"customer_input": "My tap water smells like rotten eggs. Is it safe to drink?"
}
]
}Nu kunnen we het experiment opzetten met een meer traditionele evaluatie, waarbij we een groot taalmodel als beoordelaar gebruiken (Volledige implementatie hier):
def classify(customer_input):
CALL_TYPES = [
"RESTORE", "ABATEMENT", "AMR (METERING)", "BILLING", "BPCS (BROKEN PIPE)", "BTR/O (BAD TASTE & ODOR)",
"C/I - DEP (CAVE IN/DEPRESSION)", "CEMENT", "CHOKED DRAIN", "CLAIMS", "COMPOST"
]
model = ChatAnthropic(model='claude-3-7-sonnet-latest')
prompt = f"""
You are a customer service AI for a water utility company. Classify the following customer input into one of these categories:
{', '.join(CALL_TYPES)}
Customer input: "{customer_input}"
Respond with just the category name, nothing else.
"""
# Get the response from Claude
response = model.invoke(prompt)
predicted_type = response.content.strip()
return predicted_typeDoor alleen de tekst door te geven aan een groot taalmodel (LLM), kunnen we de echte klassekennis isoleren van de geëxtraheerde klasse die wordt geretourneerd en deze vergelijken.
def compare(customer_input, actual_type)
predicted_type = classify(customer_input)
result = {
"id": call["id"],
"customer_input": customer_input,
"actual_type": actual_type,
"predicted_type": predicted_type,
"correct": actual_type == predicted_type
}
return resultHet uitvoeren hiervan op de volledige synthetische dataset met behulp van Claude 3.7 Sonnet (het nieuwste model, op het moment van schrijven) levert zeer hoge prestaties op, waarbij 91% van de oproepen nauwkeurig wordt geclassificeerd:
"metrics": {
"overall_accuracy": 0.91,
"correct": 91,
"total": 100
}Zelfs als dit echte telefoongesprekken waren en we niet vooraf wisten in welke categorie ze zaten, zouden we alle 100 telefoongesprekken opnieuw moeten bekijken om de 9 verkeerd geclassificeerde gesprekken te vinden.
Door ons krachtige besluitvormingscircuit hierboven toe te passen, verkrijgen we vergelijkbare nauwkeurigheidsresultaten samen met Vertrouwen In die antwoorden. In dit geval is de algehele nauwkeurigheid 87%, maar de nauwkeurigheid van onze antwoorden met een hoog betrouwbaarheidsniveau bedraagt 92.5%.
{
"metrics": {
"overall_accuracy": 0.87,
"correct": 87,
"total": 100
},
"confidence_metrics": {
"high": {
"count": 80,
"correct": 74,
"accuracy": 0.925
},
"medium": {
"count": 18,
"correct": 13,
"accuracy": 0.722
},
"low": {
"count": 2,
"correct": 0,
"accuracy": 0.0
}
}
}Onze antwoorden moeten 100% nauwkeurig zijn en moeten met een hoge mate van zekerheid worden gegeven. Er valt dus nog veel werk te verzetten. Wat deze aanpak ons in staat stelt te doen is ons te verdiepen in reden Onnauwkeurigheid van antwoorden met hoge zekerheid. In dit geval worden met zwakke beweringen en eenvoudige verificatiemogelijkheden niet alle problemen ondervangen, wat leidt tot classificatiefouten. Deze mogelijkheden kunnen iteratief worden verbeterd om een nauwkeurigheid van 100% te bereiken bij antwoorden met een hoge mate van betrouwbaarheid.
Verbeteringen aan het filtersysteem om het vertrouwen in de resultaten te vergroten.
Het huidige systeem classificeert reacties als ‘met hoge zekerheid’ wanneer de primaire en reserve-analisten het eens zijn. Om een hogere nauwkeurigheid te bereiken, moeten we selectiever zijn in wat we als ‘hoge betrouwbaarheid’ beschouwen.
# Modified high confidence logic
if (primary_result['call_type'] == backup_result['call_type'] and
primary_result['call_type'] is not None and
validation_result and
negative_check == 'yes' and
additional_validation_metrics > threshold):
return {'call_type': primary_result['call_type'], "confidence": "high"}Door extra kwalificatiecriteria toe te voegen, krijgen we minder resultaten met ‘hoge betrouwbaarheid’, maar deze zullen wel nauwkeuriger zijn. Deze verbetering in het filtersysteem is gericht op het verminderen van fouten en het verhogen van de betrouwbaarheid van gegevens die als hoge kwaliteit zijn geclassificeerd.
Aanvullende verificatietechnieken: de nauwkeurigheid van de analyse verbeteren
Hier zijn enkele andere ideeën om uw gegevensvalidatie- en analyseproces te verbeteren:
Tertiaire analysatorVoeg een derde onafhankelijke analysemethode toe. Deze methode dient als een extra verificatielaag, waarbij de resultaten van twee verschillende analysemethoden worden vergeleken met de resultaten van een derde methode. Zo wordt een grotere nauwkeurigheid gegarandeerd en de kans op fouten verkleind.
# Only mark high confidence if all three agree
if primary_result['call_type'] == backup_result['call_type'] == tertiary_result['call_type']:Historische patroonherkenning:Vergelijk de resultaten met historisch correcte resultaten (denk aan vectoronderzoek). Deze techniek gebruikt betrouwbare historische gegevens als referentie en vergelijkt de huidige resultaten hiermee om afwijkingen of inconsistenties te identificeren. Het kan worden beschouwd als een soort ‘geheugen’ voor analyse, dat helpt bij het detecteren van afwijkingen of onverwachte situaties.
if similarity_to_known_correct_cases(primary_result) > 0.95:Tegenstrijdige testenPas kleine variaties toe op de invoer en controleer of de classificatie stabiel blijft. Deze methode is erop gericht de robuustheid en robuustheid van een classificatiesysteem te testen door het bloot te stellen aan kleine wijzigingen in de gegevens. Als het systeem erg gevoelig is voor dit soort veranderingen, kan dit wijzen op mogelijke zwakheden of vooroordelen.
variations = generate_input_variations(customer_input)
if all(analyze_call_type(var) == primary_result['call_type'] for var in variations):
Algemene formule voor menselijke interventies in een LLM-extractiesysteem
De volledige afleiding is hier beschikbaar..
- N = Totaal aantal executies (10,000 in ons voorbeeld)
- p_1 = nauwkeurigheid van de basisparser (0.8 in ons voorbeeld)
- p_2 = nauwkeurigheid van de fallback-parser (0.8 in ons voorbeeld)
- v = effectiviteit van de schemavalidator (0.7 in ons voorbeeld)
- n = effectiviteit van de negatieve checker (0.6 in ons voorbeeld)
- H = aantal menselijke interventies vereist
- E_final = definitieve onontdekte fouten
- m = aantal onafhankelijke accountants
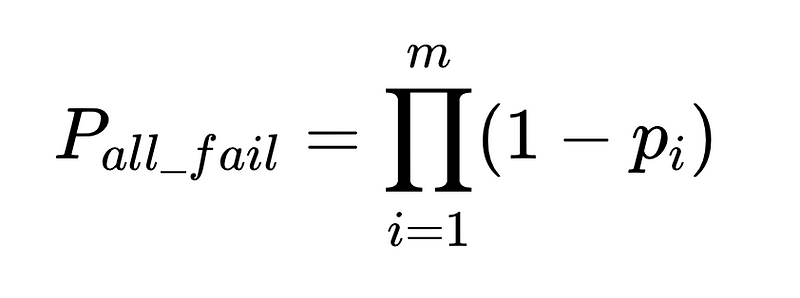
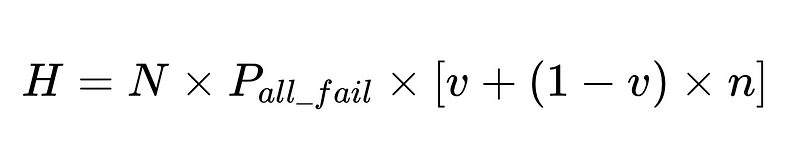
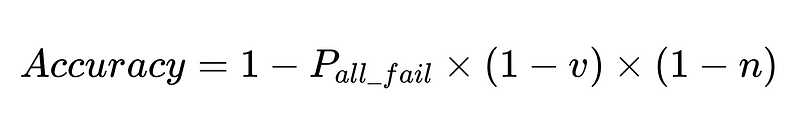
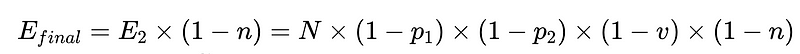
Optimaal systeemontwerp
De vergelijking geeft belangrijke inzichten in de nauwkeurigheid van een systeem voor natuurlijke taalverwerking (NLP):
- Door parsers toe te voegen wordt de overhead verminderd, maar de algehele nauwkeurigheid verbeterd.
- De nauwkeurigheid van het systeem wordt beperkt door:
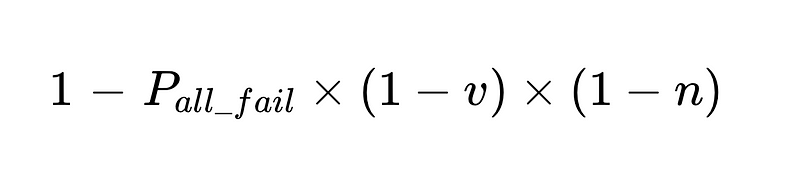
- Menselijke interventies zijn proportioneel Direct Met een totaal van N executies.
Bijvoorbeeld:
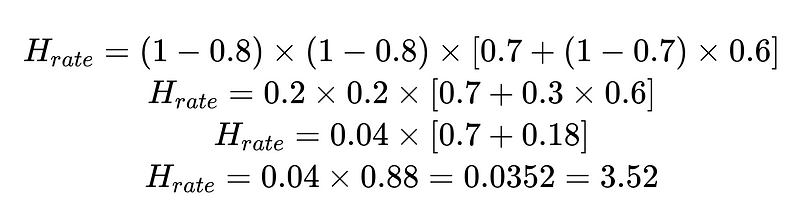
Met de berekende menselijke interventiesnelheid (H_rate) kunnen we de effectiviteit van onze oplossing in realtime volgen. Als het percentage menselijke tussenkomst boven de 3.5% komt, weten we dat het systeem faalt. Als het percentage menselijke tussenkomst structureel daalt tot onder de 3.5%, weten we dat onze optimalisaties werken zoals verwacht.
kostenfunctie
We kunnen ook een kostenfunctie creëren waarmee we ons systeem kunnen verbeteren. De kostenfunctie is een krachtig analytisch hulpmiddel voor het evalueren van de financiële prestaties van een systeem en het identificeren van mogelijke verbeterpunten.
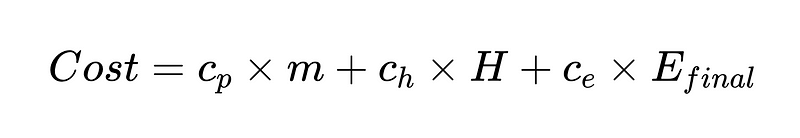
waar:
- c_p = lopende kosten per parser ($0.10 in ons voorbeeld)
- m = aantal keren dat de parser wordt uitgevoerd (in ons voorbeeld 2 * N)
- H = Aantal gevallen waarvoor menselijke tussenkomst vereist is (352 in ons voorbeeld)
- c_h = kosten van één menselijke interventie ($200 bijvoorbeeld: 4 uur @ $50/uur)
- c_e = kosten van één onopgemerkte fout (bijv. $1000)
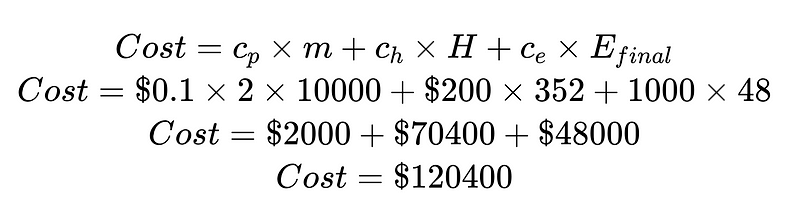
Door de kosten te delen door de kosten van menselijk ingrijpen en de kosten van onopgemerkte fouten, kunnen we het totale systeem verbeteren. In dit voorbeeld, als de kosten van menselijk ingrijpen ($ 70,400) ongewenst en hoog zijn, kunnen we ons richten op het verbeteren van resultaten met een hoge betrouwbaarheid. Als de kosten van onopgemerkte fouten ($ 48,000) ongewenst en hoog zijn, kunnen we Plus-syntaxisanalysatoren introduceren om het percentage onopgemerkte fouten te verlagen.
Kostenfuncties zijn uiteraard het meest bruikbaar om te onderzoeken hoe de situaties die ze beschrijven, verbeterd kunnen worden.
Vanuit het bovenstaande scenario kan het aantal onontdekte fouten, E_final, met 50% worden verminderd, waarbij
- p1 en p2 = 0.8,
- v = 0.7 en
- n = 0.6
We hebben drie opties:
- Er is een nieuwe grammaticaparser met een nauwkeurigheid van 50% toegevoegd als secundaire parser. Let wel, dit heeft een keerzijde: de kosten voor het gebruik van de Plus-grammaticaparsers stijgen, samen met de hogere kosten voor menselijke tussenkomst.
- Verbeter bestaande grammaticaparsers met elk 10%. Dit is niet altijd mogelijk, maar ook niet altijd vanwege de moeilijkheidsgraad van de taak die deze syntactische analysatoren uitvoeren.
- Verbeter het auditproces met 15%. Dit verhoogt opnieuw de kosten door menselijk ingrijpen.
De toekomst van AI-vertrouwen: vertrouwen opbouwen door extreme precisie
Naarmate AI-systemen steeds meer worden geïntegreerd in belangrijke aspecten van het bedrijfsleven en de maatschappij, wordt het nastreven van optimale nauwkeurigheid steeds belangrijker, vooral in kritische toepassingen. Door deze op circuits gebaseerde benaderingen toe te passen op AI-besluitvorming, kunnen we systemen bouwen die niet alleen efficiënt schalen, maar ook het diepe vertrouwen opbouwen dat alleen voortkomt uit consistente, betrouwbare prestaties. De toekomst ligt niet in krachtigere individuele modellen, maar in zorgvuldig ontworpen systemen die meerdere perspectieven combineren met strategisch menselijk toezicht.
Net zoals digitale elektronica zich ontwikkelde van onbetrouwbare componenten tot computers waaraan we onze belangrijkste gegevens toevertrouwen, zijn AI-systemen nu bezig met een vergelijkbaar traject. De frameworks die in dit artikel worden beschreven, vormen de blauwdrukken voor wat uiteindelijk de standaardarchitectuur voor bedrijfskritische AI zal worden: systemen die niet alleen betrouwbaarheid beloven, maar deze ook wiskundig garanderen. De vraag is niet langer of we AI-systemen kunnen bouwen die vrijwel perfect nauwkeurig zijn, maar hoe snel we deze principes kunnen implementeren in onze belangrijkste toepassingen.
Reacties zijn gesloten.