

Prestatie-evaluatie van DeepSeek-R1-gedistilleerde modellen op GPQA met behulp van Ollama en eenvoudige evaluaties van OpenAI
Stel de GPQA-Diamond-benchmark in en voer deze uit op lokaal gedistilleerde DeepSeek-R1-modellen om hun inferentiecapaciteiten te evalueren.
Lancering van het nieuwste model DeepSeek-R1 Breed gedragen binnen de wereldwijde AI-gemeenschap. Er zijn doorbraken bereikt die vergelijkbaar zijn met de inferentiemodellen van Meta en OpenAI, en dat bovendien in een fractie van de tijd en tegen veel lagere kosten.
Maar hoe kunnen we, afgezien van alle krantenkoppen en online hype, de inferentiecapaciteiten van een model evalueren op basis van erkende criteria? Dit is een belangrijke vraag voor AI-experts.
. Gebruikersomgeving Diep zoeken Het is niet alleen eenvoudig om de mogelijkheden ervan te verkennen, maar als u het programmatisch gebruikt, krijgt u ook diepere inzichten en kunt u het probleemloos integreren in echte toepassingen. Door inzicht te krijgen in hoe deze modellen lokaal werken, verbetert u de controle en offline toegang.

In dit artikel gaan we onderzoeken hoe je Ollama و eenvoudige evaluaties van OpenAI Om de inferentiemogelijkheden van DeepSeek-R1-gedistilleerde modellen te evalueren op basis van de benchmark GPQA-Diamant beroemd Dit criterium wordt beschouwd als een van de belangrijkste hulpmiddelen voor het evalueren van modellen van kunstmatige intelligentie op het gebied van logisch redeneren.
aan jou GitHub-repositorylink Zie bij dit artikel.
(1) Wat zijn de modellen van redeneren?
Inferentiemodellen, zoals DeepSeek-R1 en de o-seriemodellen van OpenAI (bijv. o1, o3), zijn grote taalmodellen (LLM's) die met behulp van reinforcement learning zijn getraind om gevolgtrekkingen uit te voeren. Deze modellen zijn geavanceerde hulpmiddelen op het gebied van kunstmatige intelligentie. Ze vormen het hoogtepunt van de evolutie in het vermogen van machines om logisch te denken en complexe problemen op te lossen.
Heuristiek wordt gekenmerkt door diep nadenken voordat er wordt geantwoord. Er worden een aantal lange interne gedachten geproduceerd voordat er wordt gereageerd. Het is uitstekend geschikt voor het oplossen van complexe problemen, programmeren, wetenschappelijk redeneren en het plannen van meerdere stappen in agentworkflows. Deze vaardigheden maken ze onmisbaar in sectoren als geavanceerde softwareontwikkeling, wetenschappelijk onderzoek en complexe procesautomatisering.
(2) Wat is het DeepSeek-R1-model?
DeepSeek-R1 is een state-of-the-art open-source groot taalmodel (LLM), speciaal ontworpen voor Geavanceerd redeneren. Ingediend in januari 2025 in het onderzoeksartikel "DeepSeek-R1: het vergroten van het inferentievermogen in grote taalmodellen met reinforcement learning". DeepSeek-R1 is een baanbrekend model op het gebied van kunstmatige intelligentie.
Dit model is gebaseerd op een LLM-architectuur (Large Language Model) met 671 miljard parameters en is getraind met behulp van uitgebreid versterkingsleren (RL) op basis van het volgende pad:
- Er zijn twee fasen van augmentatie die erop gericht zijn verbeterde redeneerpatronen te ontdekken en deze af te stemmen op menselijke voorkeuren.
- Twee fasen van begeleide fijnafstemming dienen als basis voor de inferentie- en niet-inferentiecapaciteiten van het model.
Ter illustratie: DeepSeek heeft twee modellen getraind:
- Het eerste model, DeepSeek-R1-Zero, is een inferentiemodel dat is getraind met behulp van reinforcement learning, en genereert gegevens om het tweede model te trainen, DeepSeek-R1.
- Dit wordt bereikt door het produceren van gevolgtrekkingen, waarvan alleen de kwalitatief hoogwaardige uitkomsten worden bewaard op basis van de uiteindelijke resultaten.
- Dit betekent dat, in tegenstelling tot de meeste modellen, de reinforcement learning (RL)-voorbeelden in deze trainingspijplijn niet door mensen worden samengesteld, maar door het model zelf worden gegenereerd.
Het resultaat is dat het model vergelijkbare prestaties behaalde als toonaangevende modellen zoals Het o1-model van OpenAI Bij taken zoals wiskunde, programmeren en complex redeneren.
(3) Inzicht in het destillatieproces en de gedestilleerde modellen van DeepSeek-R1
Naast het volledige model hebben ze ook zes kleinere, dichte modellen (ook wel DeepSeek-R1 genoemd) van verschillende groottes (1.5B, 7B, 8B, 14B, 32B, 70B) open source gemaakt, die zijn afgeleid van DeepSeek-R1 op basis van Qwen أو Lama Als basismodel.
Distillatie Het is een techniek waarbij een kleiner model (‘student’) wordt getraind om de prestaties van een groter, krachtiger model dat eerder is getraind (‘leraar’) te repliceren.
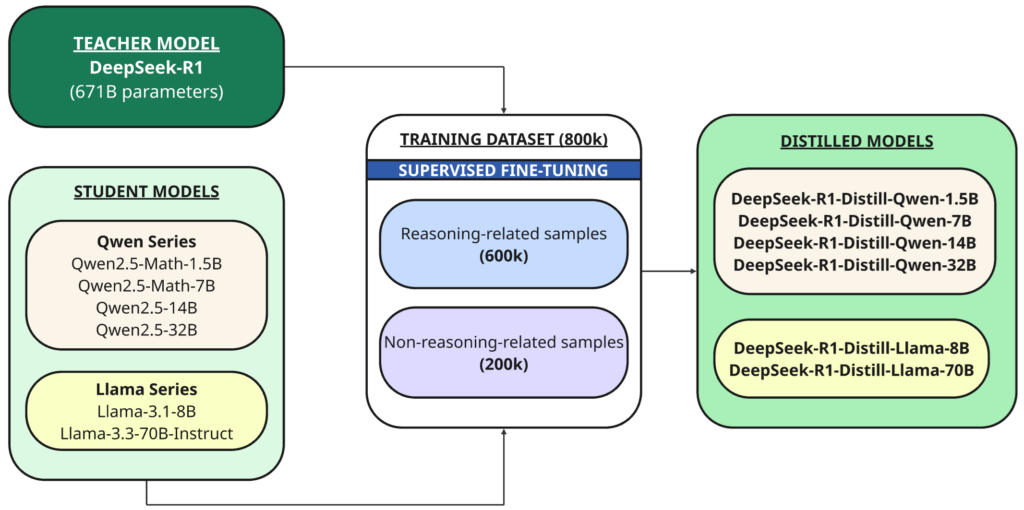
In dit geval is de docent het 1B DeepSeek-R671-model en de studenten zijn de zes modellen die zijn gedistilleerd met behulp van dit open-source basismodel:
- Qwen2.5 — Wiskunde-1.5B
- Qwen2.5 — Wiskunde-7B
- Qwen2.5 — 14B
- Qwen2.5 — 32B
- Lama-3.1 — 8B
- Llama-3.3 — 70B-Instructie
DeepSeek-R1 werd gebruikt als een model voor docenten om 800,000 trainingsmonsters te genereren, een mengsel van inferentie- en niet-inferentiemonsters, voor distillatie door begeleide fine-tuning Voor basismodellen (1.5B, 7B, 8B, 14B, 32B en 70B).
Waarom distilleren we eigenlijk?
Het doel is om de inferentiecapaciteiten van grotere modellen, zoals DeepSeek-R1 671B, over te brengen naar kleinere, efficiëntere modellen. Hierdoor kunnen kleinere modellen complexe inferentietaken sneller uitvoeren en efficiënter gebruikmaken van bronnen.
Bovendien heeft DeepSeek-R1 een enorm aantal parameters (671 miljard), waardoor het op de meeste consumentenapparaten lastig te gebruiken is.
Zelfs de krachtigste MacBook Pro, met een maximaal gecombineerd geheugen van 128 GB, is niet voldoende om een model met parameters van 671 miljard te laten draaien.
Gedistilleerde modellen bieden de mogelijkheid om ze in te zetten op apparaten met beperkte rekenkracht.
bereikt Onluiheid Een opmerkelijke prestatie door het oorspronkelijke DeepSeek-R1-model met 671 miljard parameters te kwantificeren tot slechts 131 GB – een opmerkelijke verkleining van 80%. De vereiste van 131 GB VRAM blijft echter een groot obstakel, vooral voor ontwikkelaars die werken met apparaten met beperkte bronnen. Deze prestatie vormt een belangrijke stap in de richting van het toegankelijk maken van grote AI-modellen voor een breder scala aan gebruikers.
(4) Selectie van het optimale gedistilleerde model
U kunt kiezen uit zes verschillende formaten gedistilleerde modellen. De keuze van het juiste model hangt grotendeels af van de mogelijkheden van uw lokale apparatuur.
Voor gebruikers met krachtige GPU's of CPU's die maximale prestaties nodig hebben, zijn de grotere DeepSeek-R1-modellen (32B en hoger) ideaal. Zelfs de quantum 671B-versie is hiervoor geschikt.
Als de middelen echter beperkt zijn of u de voorkeur geeft aan snellere bouwtijden (zoals ik), zijn kleinere gedistilleerde varianten, zoals 8B of 14B, een betere optie. Hiermee wordt een evenwicht gevonden tussen prestatie- en resourcevereisten.
Voor dit project gebruik ik het gedistilleerde DeepSeek-R1-model. Qwen-14B, wat overeenkomt met de hardwarebeperkingen die u bent tegengekomen. Dit model (14B) vertegenwoordigt een uitstekend compromis tussen nauwkeurigheid en snelheid, waardoor het perfect past bij mijn ontwikkelomgeving.
(5) Criteria voor het evalueren van het inferentievermogen van grote taalmodellen
Grote taalmodellen (LLM's) worden doorgaans geëvalueerd aan de hand van gestandaardiseerde metrieken die de prestaties ervan bij verschillende taken bepalen, waaronder taalbegrip, codegeneratie, het volgen van instructies en het beantwoorden van vragen. Veelvoorkomende voorbeelden zijn statistieken zoals: MMLU, En MenselijkEval, En MGSM. Deze metrieken zijn essentieel voor het evalueren van de mogelijkheden van grote taalmodellen.
Om het redeneervermogen van een groot taalmodel te meten, hebben we uitdagendere benchmarks nodig die zich sterk richten op redeneren en verder gaan dan oppervlakkige taken. Hier zijn enkele veelvoorkomende voorbeelden die gericht zijn op het beoordelen van geavanceerde redeneervaardigheden:
(i) AIME 2024-examen: Competitieve wiskunde
- Bereiden Amerikaans uitnodigingsexamen wiskunde (AIME) 2024 Een robuuste maatstaf voor het evalueren van de mogelijkheden van grote taalmodellen (LLM's) in wiskundig redeneren.
- Dit examen vormt een grote uitdaging binnen de competitieve wiskunde, omdat het complexe problemen met meerdere stappen bevat. Bij dit examen wordt het vermogen van grote taalmodellen getest om complexe vragen te begrijpen, geavanceerde redeneringen toe te passen en nauwkeurige symbolische manipulaties uit te voeren. De AIME is een belangrijke maatstaf voor het beoordelen van complexe wiskundige probleemoplossende vaardigheden.
(ii) Codeforces – Competitiecode
- sta op Codeforces Standaard Evalueren van het inferentievermogen van een groot taalmodel (LLM) met behulp van echte competitieve programmeringsproblemen van Codeforces, een platform dat bekendstaat om zijn algoritmische uitdagingen. Codeforces is de gouden standaard voor het evalueren van de mogelijkheden van AI-modellen om complexe problemen op te lossen.
- Deze problemen testen het vermogen van een groot taalmodel (LLM) om complexe instructies te begrijpen, logisch en wiskundig te redeneren, oplossingen met meerdere stappen te plannen en correcte en efficiënte code te genereren. Voor deze problemen is een diepgaand begrip van algoritmen en datastructuren vereist, evenals het vermogen om het probleem om te zetten in uitvoerbare code.
(iii) GPQA Diamond – wetenschappelijke vragen op PhD-niveau
- GPQA-Diamond is een geselecteerde subset van De moeilijkste vragen Van de standaard GPQA (Postdoctorale Natuurkunde Vraag Antwoorden) De breedste variant, die specifiek is ontworpen om de grenzen van het vermogen van LLM-modellen te verleggen om afleidingen te kunnen maken in geavanceerde PhD-onderwerpen. Deze norm vormt een echte uitdaging voor het vermogen van AI om complexe wetenschappelijke concepten te begrijpen en af te leiden.
- Terwijl de GPQA een reeks conceptuele en op berekeningen gebaseerde vragen voor postdoctorale studenten omvat, richt de GPQA-Diamond zich uitsluitend op de meest uitdagende vragen en de vragen die intensief redeneren vereisen.
- Dit criterium wordt beschouwd als ‘Google-resistent’, wat betekent dat het zelfs bij onbeperkte internettoegang moeilijk is om hieraan te voldoen. Hierdoor is het een waardevol hulpmiddel voor het beoordelen van het vermogen van grote taalmodellen om zelfstandig te redeneren.
- Hier is een voorbeeld van een GPQA-Diamond-vraag:
### GPQA Diamond - Voorbeeldvraag (Moleculaire biologie) Een eukaryotische cel heeft een mechanisme ontwikkeld om macromoleculaire bouwstenen om te zetten in energie. Het proces vindt plaats in de mitochondriën, de energiefabriekjes van de cellen. In de reeks redoxreacties wordt de energie uit voedsel opgeslagen tussen de fosfaatgroepen en gebruikt als universele cellulaire valuta. De energierijke moleculen worden uit de mitochondriën getransporteerd om te dienen bij alle cellulaire processen. U heeft een nieuw medicijn tegen diabetes ontdekt en wilt onderzoeken of dit medicijn effect heeft op de mitochondriën. U voert een reeks experimenten uit met uw HEK293-cellijn. Welk van de onderstaande experimenten zal u niet helpen de mitochondriale rol van uw geneesmiddel te ontdekken? (A) Differentiële centrifugatie-extractie van mitochondriën gevolgd door de Glucose Uptake Colorimetric Assay Kit (B) Flowcytometrie na labeling met 2.5 µM 5,5',6,6'-tetrachloor-1,1',3,3'-tetraethylbenzimidazolylcarbocyaninejodide (C) Transformatie van cellen met recombinante luciferase en luminometermeting na toevoeging van 5 µM luciferine aan de supernatant (D) Confocale fluorescentiemicroscopie na Mito-RTP-kleuring van de cellen
In dit project, Wij gebruiken GPQA-Diamond als standaard voor de conclusie., zoals ik het gebruikte OpenAI و Diepzoeken Om hun inferentiemodellen te evalueren. De keuze voor GPQA-Diamond als evaluatiestandaard is een bewijs van de moeilijkheidsgraad en het belang ervan op het gebied van AI-ontwikkeling.
(6) Gebruikte hulpmiddelen
In dit project maken we voornamelijk gebruik van Ollama و eenvoudige evaluaties Van OpenAI. Ollama is een krachtig platform voor het lokaal uitvoeren van grote taalmodellen, terwijl simple-evals een raamwerk biedt voor het evalueren van de prestaties van deze modellen.
(i) Ollama
Ollama Het is een open source-tool waarmee u eenvoudig grote taalmodellen (LLM's) op uw computer of op een lokale server kunt uitvoeren. Olama is een ideaal platform voor het lokaal uitvoeren van AI-modellen.
Het fungeert als beheerder en runtime en voert taken uit zoals downloads en het instellen van de omgeving. Hierdoor kunnen gebruikers met deze modellen communiceren zonder dat ze continu een internetverbinding nodig hebben of afhankelijk zijn van cloudservices. Het beheren van lokale grote taalmodellen (LLM's) is een kernfunctie van Olama.
Het ondersteunt veel grote open source-taalmodellen, waaronder DeepSeek-R1, en is platformonafhankelijk compatibel met macOS, Windows en Linux. Bovendien is het eenvoudig te installeren, vergt het weinig moeite en worden de bronnen efficiënt gebruikt. Met Ollama kunt u de kracht van kunstmatige intelligentie direct op uw apparaat benutten.
BelangrijkZorg ervoor dat uw lokale computer het volgende heeft: GPU-toegankelijkheid Voor Ollama zorgt dit voor een aanzienlijke prestatieverbetering en maakt het benchmarken daarna efficiënter vergeleken met de CPU. Voer de opdracht uit
nvidia-smiControleer in de terminal of de GPU wordt gedetecteerd. Met deze procedure wordt ervoor gezorgd dat de mogelijkheden van het apparaat optimaal worden benut, zodat modellen met een hoge efficiëntie kunnen worden uitgevoerd.
(ii) OpenAI simple-evals-bibliotheek voor het evalueren van taalmodellen
Bereiden eenvoudige evaluaties Een lichtgewicht bibliotheek die is ontworpen om taalmodellen te evalueren met behulp van de zero-shot-evaluatiemethode met aansturing op basis van een gedachteketen. Deze bibliotheek bevat populaire evaluatiebenchmarks zoals MMLU, MATH, GPQA, MGSM en HumanEval en is bedoeld om realistische gebruiksscenario's te simuleren om de prestaties van AI-modellen bij complexe inferentietaken te evalueren.
Sommigen van jullie zijn misschien bekend met de populairste en meest uitgebreide evaluatiebibliotheek van OpenAI, genaamd evaluaties, wat verschilt van eenvoudige evaluaties.
De pagina geeft namelijk aan README De simple-evals-specificatie geeft aan dat het niet de bedoeling is om de bibliotheek te vervangen. evaluaties.
Waarom gebruiken we eigenlijk simpele evaluaties?
Het simpele antwoord is dat eenvoudige evaluaties Het bevat ingebouwde beoordelingsteksten voor de inferentiestandaarden die wij nastreven (zoals GPQA), die in de bibliotheek ontbreken. evaluaties.
Bovendien heb ik, afgezien van simple-evals, geen andere hulpmiddelen of platformen gevonden die een directe en native manier in de taal bieden. Python Om veel belangrijke standaarden, zoals GPQA, uit te voeren, vooral bij gebruik van Ollama.
(7) Evaluatieresultaten
Als onderdeel van de evaluatie heb ik geselecteerd: 20 willekeurige vragen Uit de GPQA-Diamond-vragenset van 198 vragen om aan te werken Formulier 14B Distilleerder. In totaal duurde het 216 minuten, ofwel ongeveer 11 minuten per vraag.
Het resultaat was enigszins teleurstellend, aangezien het 10% Dit is echter aanzienlijk lager dan het gerapporteerde resultaat van 73.3% voor het 1B DeepSeek-R671-model.
Het grootste probleem dat ik heb opgemerkt is dat tijdens intensief intern redeneren, Vaak leverde het model geen enkel antwoord op (bijvoorbeeld door inferentiecodes als laatste uitvoerregels te retourneren) of gaf het een antwoord dat niet overeenkwam met het verwachte meerkeuzeformaat (bijvoorbeeld antwoord: A).
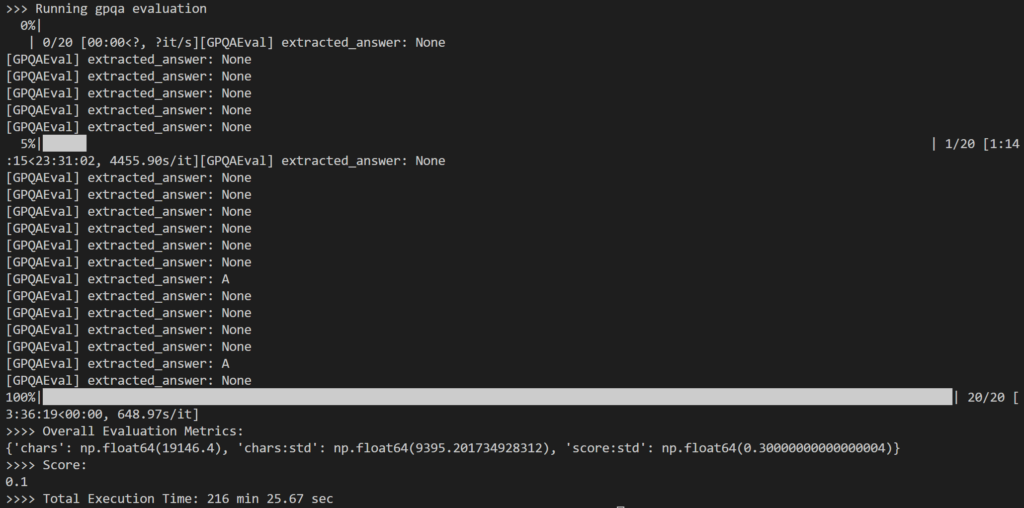
Zoals hierboven weergegeven, resulteerden veel van de uitkomsten in: None Omdat de regex-logica in simple-evals het verwachte antwoordpatroon in het LLM-antwoord niet kon detecteren.
Terwijl mensachtig redeneren Het was interessant om te zien, want ik had verwacht dat de resultaten wat betreft de nauwkeurigheid bij het beantwoorden van vragen beter zouden zijn.
Ik heb online ook gebruikers zien melden dat zelfs het grotere 32B-model niet zo goed werkt als de o1. Hierdoor zijn er twijfels ontstaan over het nut van gedistilleerde inferentiemodellen, vooral als deze moeite hebben om correcte antwoorden te geven, ondanks dat ze lange inferenties genereren.
GPQA-Diamond is echter een zeer veeleisende benchmark, waardoor deze modellen toch bruikbaar kunnen zijn voor eenvoudigere inferentietaken. Het is ook eenvoudiger omdat er minder rekenkracht nodig is.
Bovendien adviseerde het DeepSeek-team om meerdere tests uit te voeren en de resultaten te middelen als onderdeel van het benchmarkproces. Dit heb ik echter over het hoofd gezien vanwege tijdsgebrek.
(8) Gedetailleerde stapsgewijze handleiding
Tot nu toe hebben we de basisconcepten en de voornaamste conclusies behandeld.
Bent u klaar voor een praktische, technische ervaring? Dan vindt u in dit gedeelte een diepgaand inzicht in de interne mechanismen en de stapsgewijze implementatie. Deze praktische technische gids geeft u een uitgebreid inzicht in de werking van het systeem.
Om te bekijken (of kopiëren) Bijbehorende GitHub-repository Volgen. Vereisten voor de configuratie van de virtuele omgeving vindt u hier. hier.
(i) Initiële installatie – Ollama
We beginnen met het downloaden van Ollama. Bezoek
Ollama Downloadpagina, kies uw besturingssysteem en volg de bijbehorende installatie-instructies.
Zodra de installatie is voltooid, start u Ollama door te dubbelklikken op de Ollama-applicatie (voor Windows en macOS) of door de opdracht uit te voeren ollama serve In de terminal.
(ii) Initiële installatie – OpenAI eenvoudige evaluaties
De simple-evals-opstelling is relatief uniek.
Terwijl simple-evals zich presenteert als een bibliotheek, Het ontbreken van bestanden __init__.py 'In de repository' betekent dat het niet is gestructureerd als een echt Python-pakket., wat leidt tot importfouten na het lokaal klonen van de repository. Dit betekent dat het geen standaard Python-pakket is in de zin waarin het doorgaans wordt gebruikt in software engineering.
Omdat het ook niet op PyPI is gepubliceerd en standaard verpakkingsbestanden zoals setup.py أو pyproject.tomlHet kan niet worden geïnstalleerd via pip. Dit maakt het een behoorlijke uitdaging voor nieuwe ontwikkelaars.
Gelukkig kunnen we gebruik maken van Git-submodules Als een directe alternatieve oplossing. Met deze modules kunt u een Git-repository in een andere opnemen, waardoor u afhankelijkheden eenvoudiger kunt beheren.
“`html
Met een Git-submodule kunnen we de inhoud van een andere Git-repository in ons project opnemen. Bestanden worden opgehaald uit een externe opslagplaats (zoals simple-evals), maar de geschiedenis ervan wordt gescheiden gehouden.
U kunt een van de twee methoden (A of B) kiezen om de inhoud van simple-evals te extraheren:
(a) Als u mijn projectrepository kloont
Mijn projectrepository bevat al simple-evals Als submodule kunt u het volgende uitvoeren:
git submodule update --init --recursive(b) Als u het toevoegt aan een nieuw gemaakt project.
Om simple-evals handmatig als submodule toe te voegen, voert u het volgende uit:
git submodule add https://github.com/openai/simple-evals.git simple_evalsopmerking: Dat simple_evals Uiteindelijk (met onderstrepingsteken) is erg belangrijk. Het specificeert de mapnaam, waarbij in plaats daarvan een koppelteken wordt gebruikt (d.w.z. eenvoudig-evals) kunnen later tot importproblemen leiden.
Laatste stap (voor beide methoden)
Nadat u de inhoud van de repository hebt opgehaald, moet u een bestand maken. __init__.py Leeg in map simple_evals De nieuw aangemaakte eenheid kan als één geheel worden geïmporteerd. U kunt het handmatig maken of de volgende opdracht gebruiken:
touch simple_evals/__init__.py(iii) Het DeepSeek-R1-model ophalen via Ollama
De volgende stap is het downloaden van het lokaal gedistilleerde model van uw keuze (bijvoorbeeld 14B) met behulp van de volgende opdracht:
Een lijst met beschikbare DeepSeek-R1-modellen vindt u op Ollama. hier. Voor de beste prestaties raden wij u aan de nieuwste versie van de sjabloon te gebruiken.
ollama pull deepseek-r1:14b(Vierde) Geef de instellingen op
We definiëren de parameters in het YAML-instellingenbestand, zoals hieronder weergegeven:
# config/config.yaml MODEL_NAME: "deepseek-r1:14b" # Modelnaam (komt overeen met de Ollama-modellijst) MODEL_TEMPERATURE: 0.6 # Instellen tussen 0.5 en 0.7 voor DeepSeek-R1 EVAL_BENCHMARK: "gpqa" GPQA_VARIANT: "diamond" EVAL_N_EXAMPLES: 20
De modeltemperatuur is ingesteld op 0.6 (Vergeleken met de typische standaardwaarde van 0). Dit is in overeenstemming met de gebruiksaanbevelingen van DeepSeek, die een temperatuurbereik van 0.5 tot 0.7 aanbevelen (0.6 wordt aanbevolen). Om oneindige herhalingen of onsamenhangende uitvoer te voorkomen. Deze instelling is nodig om de kwaliteit van de uitvoer te verbeteren en de consistentie ervan te garanderen.
Mis de kans niet om te kijken De unieke en interessante gebruiksaanbevelingen van DeepSeek-R1 – met name voor benchmarks – om optimale prestaties te garanderen bij het gebruik van DeepSeek-R1-modellen.
EVAL_N_EXAMPLES Dit is de parameter die wordt gebruikt om het aantal vragen uit de volledige set van 198 vragen in te stellen dat in de beoordeling wordt gebruikt. Deze parameter is nodig om het evaluatieproces aan te passen aan de beschikbare middelen en de specifieke testdoelstellingen.
(v) De samplercode instellen
Om Ollama-gebaseerde taalmodellen binnen het simple-evals-framework te ondersteunen, maken we een aangepaste wrapperklasse met de naam OllamaSampler En houd het binnen utils/samplers/ollama_sampler.py. Sampler is een essentieel onderdeel bij het testen en evalueren van de prestaties van taalmodellen.
# utils/samplers/ollama_sampler.py importeer ollama klasse OllamaSampler: def __init__(zelf, model_naam=Geen, temperatuur=0): zelf.model_naam = model_naam zelf.temperatuur = temperatuur def __call__(zelf, prompt_berichten): prompt_tekst = prompt_berichten[-1]["inhoud"] response = ollama.chat( model=zelf.model_naam, berichten=[{"rol": "gebruiker", "inhoud": prompt_tekst}], opties={"temperatuur": zelf.temperatuur} ) response_inhoud = response["bericht"]["inhoud"] return response_inhoud def _pack_bericht(zelf, inhoud, rol): return {"rol": rol, "inhoud": inhoud}
In deze context betekent het merklap (Samplifier) Een Python-klasse die uitvoer genereert van een taalmodel op basis van een gegeven prompt. Deze tool is cruciaal om te garanderen dat het model uiteenlopende en representatieve antwoorden genereert.
Omdat de samplers in simple-evals alleen providers zoals OpenAI en Claude bestrijken, hebben we een samplerklasse nodig die een interface biedt die compatibel is met Ollama. Dit zorgt voor een naadloze integratie met het beoordelingskader.
sta op OllamaSampler Haalt een GPQA-vraag op, verstuurt deze naar het formulier bij een opgegeven temperatuur en retourneert een antwoord in platte tekst. Temperatuur is een belangrijke parameter die de willekeur van de uitvoer bepaalt.
Methode inbegrepen _pack_message Om ervoor te zorgen dat de uitvoeropmaak overeenkomt met wat de evaluatiescripts in simple-evals verwachten. Dit zorgt voor consistentie en eenvoudige analyse.
6. Maak een evaluatiescript
De volgende code laat zien hoe u een evaluatie-implementatie in een bestand instelt. main.py, inclusief het gebruik van de categorie GPQAEval Vanuit de simple-evals-bibliotheek om GPQA-benchmarktests uit te voeren.
Functie run_eval() Het is een configureerbare evaluatie-runtimetool die grote taalmodellen (LLM's) via Ollama test op basis van standaarden zoals GPQA. Deze functie is nodig om de prestaties van modellen nauwkeurig te evalueren.
# main.py def run_eval(): start_time = time.time() # Configuratiebestand laden config = load_config("config/config.yaml") # Ollama-sampler initialiseren (wrapper rond Ollama-chat) ollama_sampler = OllamaSampler(model_name=config["MODEL_NAME"], temperature=config["MODEL_TEMPERATURE"] ) # Evaluatieklasse selecteren die moet worden gebruikt op basis van EVAL_BENCHMARK eval_benchmark = config["EVAL_BENCHMARK"] # GPQA print(f">>> {eval_benchmark} evaluatie uitvoeren") if eval_benchmark == "gpqa": eval_class = GPQAEval eval_kwargs = { "n_repeats": config["EVAL_N_REPEATS"], # Standaard 1 "num_examples": config["EVAL_N_EXAMPLES"], # Stel in op 20 "variant": config["GPQA_VARIANT"], # GPQA-Diamond subset } anders: raise ValueError( f"Onbekende EVAL_BENCHMARK '{eval_benchmark}'." ) # Instantieer en voer de juiste evaluatie uit evaluator = eval_class(**eval_kwargs) results = evaluator(ollama_sampler) # Voer de evaluatie uit met de sampler end_time = time.time() elapsed_seconds = end_time - start_time minutes, seconds = divmod(elapsed_seconds, 60) # Bereken de totale benodigde tijd # De geretourneerde resultaten zijn een EvalResult met een lijst met SingleEvalResult en samengevoegde statistieken print(">>>> Algemene evaluatiestatistieken:", results.metrics) print(">>>> Score:", results.score) print(f">>>> Totale uitvoeringstijd: {int(minuten)} min {seconden:.2f} sec") if __name__ == "__main__": # Voer GPQA-evaluatie-uitvoering uit run_eval()
De functie laadt de instellingen uit het configuratiebestand, stelt de juiste evaluatieklasse in op basis van simple-evals en voert het model uit via een uniform evaluatieproces. Het wordt opgeslagen in een bestand. main.py, die kan worden uitgevoerd met behulp van de opdracht python main.py. Dit zorgt voor een consistent en herhaalbaar evaluatieproces.
Door de bovenstaande stappen te volgen, hebben we met succes de GPQA-Diamond-benchmark op het gedistilleerde DeepSeek-R1-model opgezet en uitgevoerd. Dit proces levert waardevolle inzichten op in de mogelijkheden van het model.
het komt neer op
In dit artikel onderzoeken we hoe we hulpmiddelen zoals Ollama en OpenAI's simple-evals kunnen combineren om modellen die zijn gedestilleerd uit DeepSeek-R1 te onderzoeken en te evalueren, met een focus op Prestatie-evaluatie van grote taalmodellen.
De gedistilleerde modellen komen mogelijk nog niet overeen met het oorspronkelijke model met 671 miljard parameters bij uitdagende inferentiebenchmarks zoals GPQA-Diamond. Het illustreert echter wel hoe distillatie de toegang tot de inferentiemogelijkheden van grote taalmodellen (LLM's) kan vergroten. Verbetering van de toegang tot grote taalmodellen Het is een belangrijk doel op dit gebied.
Ondanks de lagere prestaties bij complexe taken op PhD-niveau, kunnen deze kleinere varianten nog steeds toepasbaar zijn in minder veeleisende scenario's, wat de weg vrijmaakt voor efficiënte lokale implementatie op een breder scala aan apparaten. Dit draagt bij aan Grote taalmodellen lokaal implementeren Efficiënt.
Reacties zijn gesloten.