

Waarom de meeste cybersecurityrisicomodellen mislukken voordat ze van start gaan
De noodzaak van kwantitatief denken over cyberbeveiligingsrisico's
Cybersecurityleiders staan voor onmogelijke vragen. "Hoe groot is de kans op een beveiligingsinbreuk dit jaar?" en "Hoeveel gaat het kosten?" en “Hoeveel moeten we uitgeven om dit te stoppen?”
De meeste risicomodellen die vandaag de dag worden gebruikt, zijn echter nog steeds gebaseerd op gissingen, instinct en met kleur gecodeerde risicokaarten, en niet op data.
Ik heb in feite gevonden PwC's 2025 Global Digital Trust Insights Study Slechts 15% van de organisaties maakt in significante mate gebruik van kwantitatieve risicomodellering.
In dit artikel onderzoeken we waarom traditionele modellen voor cyberbeveiligingsrisico's tekortschieten en hoe het toepassen van eenvoudige statistische hulpmiddelen, zoals probabilistische modellering, een betere oplossing biedt.

Twee hoofdstromingen in het modelleren van cyberrisico's
Cyberrisicomodellen zijn: Systematische kaders of methoden die worden gebruikt om cyberbeveiligingsbedreigingen en hun potentiële impact op informatiesystemen, gegevens of bedrijven te analyseren, evalueren en meten.
Professionals op het gebied van informatiebeveiliging gebruiken tijdens het risicobeoordelingsproces voornamelijk twee verschillende methoden voor risicomodellering: kwalitatief en kwantitatief. Het wordt beschouwd Kwantitatieve modellering van cyberrisico's Een geavanceerde techniek waarvoor specialistische kennis vereist is.
Kwalitatieve modellen voor risicobeoordeling
Stel je voor dat twee teams hetzelfde risico beoordelen. Het risico krijgt een score van 4/5 voor waarschijnlijkheid en 5/5 voor impact. Het andere team geeft haar 3/5 en 4/5. Beide teams plaatsen het op een matrix. Maar geen van beiden kan de vraag van de CFO beantwoorden: "Hoe waarschijnlijk is het dat dit daadwerkelijk zal gebeuren, en wat gaat het ons kosten?"
De kwalitatieve benadering is gebaseerd op subjectieve risicobeoordeling en komt hoofdzakelijk voort uit de intuïtie van de evaluator. Bij een kwalitatieve benadering worden de waarschijnlijkheid en impact van risico's doorgaans beoordeeld op een ordinale schaal, bijvoorbeeld van 1 tot 5.
Vervolgens worden de risico's in de risicomatrix geplaatst om inzicht te krijgen in hun positie op deze schaal.
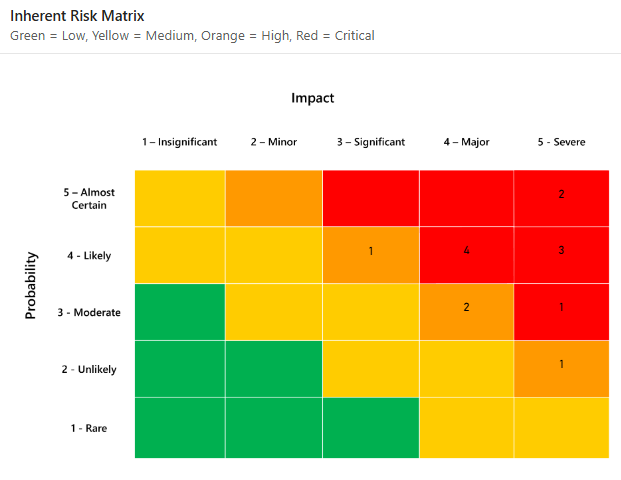
De twee ordinale schalen worden vaak met elkaar vermenigvuldigd om de belangrijkste risico's te prioriteren op basis van waarschijnlijkheid en impact. Op het eerste gezicht lijkt dit redelijk, aangezien de meest gebruikte definitie van risico in de informatiebeveiliging als volgt luidt:
[tekst{Risico} = tekst{Waarschijnlijkheid} maal tekst{Impact}]
Statistisch gezien brengt kwalitatieve risicomodellering echter een aantal zeer aanzienlijke risico's met zich mee.
Het eerste risico is het gebruik van ordinale schalen. Hoewel het toekennen van getallen aan de ordinale schaal de schijn wekt van wiskundige ondersteuning voor het model, is dit slechts een illusie.
Ordinale schalen zijn simpelweg labels – er is geen vaste afstand tussen de schalen. De afstand tussen een risico met impact “2” en een impact “3” is niet kwantificeerbaar. Het veranderen van de labels op de ordinale schaal naar “A”, “B”, “C”, “D” en “E” maakt geen verschil.
Dit betekent dat de manier waarop wij risico's formuleren, niet klopt als we kwalitatieve modellen gebruiken. Het is onmogelijk om de waarschijnlijkheid van “B” te vermenigvuldigen met het effect van “C”.
Een andere grote valkuil is het modelleren van onzekerheid. Wanneer we cyberrisico's modelleren, modelleren we onzekere toekomstige gebeurtenissen. Er zijn in feite verschillende uitkomsten mogelijk.
Als cyberrisico's worden samengevat in schattingen op één punt (zoals '20/25' of 'Hoog'), wordt het belangrijke onderscheid tussen 'het meest waarschijnlijke jaarlijkse verlies is $ 1 miljoen' en 'er is een kans van 5% op een verlies van $ 10 miljoen of meer' niet vastgelegd.
Kwantitatieve risicomodellering: geavanceerde analyse
Stel je een team voor dat een risicobeoordeling uitvoert. Ze schatten dat de opbrengsten uiteenlopen van $ 100 tot $ 10 miljoen. Door een Monte Carlo-simulatie uit te voeren, schatten ze dat er een kans van 10% is dat de jaarlijkse verliezen meer dan $ 480 miljoen bedragen en dat het verwachte verlies $ XNUMX bedraagt. Nu de CFO vraagt: Hoe groot is de kans dat dit gebeurt, en wat gaat het kosten?Het team kan reageren met data, en niet alleen met intuïtie.
Deze aanpak verschuift het gesprek van vage risicoclassificaties naar Mogelijkheden en potentiële financiële impact, een taal die leidinggevenden begrijpen.
Als u een achtergrond in statistiek hebt, zal één concept hier in het bijzonder opvallen:
Waarschijnlijkheid.
Bij het modelleren van cyberbeveiligingsrisico's wordt in essentie geprobeerd de waarschijnlijkheid dat bepaalde gebeurtenissen zich voordoen en de impact ervan te kwantificeren. Dit opent de deur naar een scala aan statistische hulpmiddelen, zoals Monte Carlo-simulatie, waarmee onzekerheid veel effectiever kan worden gemodelleerd dan ordinale metingen.
Bij kwantitatieve risicomodellering worden statistische modellen gebruikt om geldbedragen toe te kennen aan verliezen en de waarschijnlijkheid te modelleren dat deze verliesgebeurtenissen zich voordoen, waarbij toekomstige onzekerheid wordt vastgelegd.
Hoewel kwalitatieve analyse soms de meest waarschijnlijke uitkomst kan benaderen, slaagt het er niet in om het volledige scala aan onzekerheden vast te leggen, zoals zeldzame maar impactvolle gebeurtenissen, bekend als 'long tail risk'.
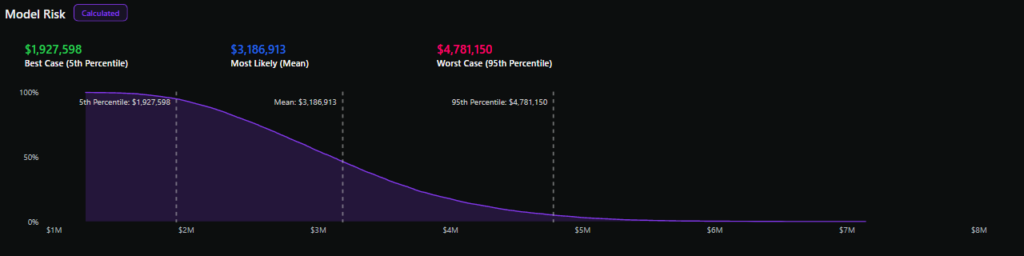
De verliesoverschotcurve geeft de waarschijnlijkheid van het overschrijden van een bepaald jaarlijks verliesbedrag op de y-as weer en verschillende verliesbedragen op de x-as, wat resulteert in een dalende lijn.
Door verschillende percentages uit de verliesoverschotcurve te halen, zoals het 90e percentiel, de mediaan en het XNUMXe percentiel, kunt u met XNUMX% zekerheid een idee krijgen van de potentiële jaarlijkse verliezen voor een risico.
Terwijl een enkelvoudige schatting van kwalitatieve analyse de meest waarschijnlijke risico's kan benaderen (afhankelijk van de nauwkeurigheid van het oordeel van de evaluatoren), houdt kwantitatieve analyse rekening met de onzekerheid in uitkomsten, zelfs die welke zeldzaam maar nog steeds mogelijk zijn (bekend als "long-tail-risico").
Verder kijken dan cyberrisico's: risicomodellen in cyberbeveiliging verbeteren
Om onze risicomodellen op het gebied van informatiebeveiliging te verbeteren, hoeven we alleen maar naar buiten te kijken en specifiek naar de technologieën die in andere vakgebieden worden gebruikt. Risicomodellen zijn in uiteenlopende toepassingen aanzienlijk geëvolueerd, bijvoorbeeld in de financiële wereld, verzekeringen, luchtvaartveiligheid en toeleveringsketenbeheer. Deze gebieden leveren waardevolle inzichten op die kunnen worden toegepast op cyberbeveiliging.
Financiële teams gebruiken modellen om het risico van beleggingsportefeuilles te beheren met behulp van vergelijkbare Bayesiaanse statistieken. Terwijl verzekeringsteams risico's modelleren met behulp van geavanceerde actuariële modellen. De luchtvaartindustrie modelleert het risico van systeemfalen met behulp van waarschijnlijkheidsmodellen. Supply chain managementteams modelleren risico's met behulp van probabilistische simulatie. Deze methodologieën vormen een solide basis voor de ontwikkeling van effectieve cyberrisicomodellen.
De tools bestaan al. De wiskundige grondslagen zijn goed begrepen. Andere sectoren hebben het pad geëffend. Het is nu tijd dat cybersecurity kwantitatieve risicomodellen omarmt, zodat er betere, meer geïnformeerde beslissingen kunnen worden genomen. Dit leidt tot betere cybersecuritystrategieën en minder potentiële verliezen. Het invoeren van deze kwantitatieve modellen is een belangrijke stap in de richting van effectiever cyberrisicobeheer.
الخلاصة الرئيسية
| Kwalitatieve analyse | Kwantitatieve analyse |
| Ordinale toonladders (1-5) | Probabilistische modellering |
| persoonlijke intuïtie | statistische nauwkeurigheid |
| Enkele evaluatiepunten | Risicoverdelingen |
| Heatmaps en kleurcodes | Verliesoverschrijdingscurven |
| Negeert zeldzame maar ernstige gebeurtenissen | Vangt risico's op de lange termijn op |
Reacties zijn gesloten.