

Uitleg: Hoe selecteert L1-regularisatie automatisch functies?
Begrijp het automatische kenmerkselectieproces dat wordt uitgevoerd door L1 (LASSO)-regularisatie.
Kenmerkselectie is het proces van het selecteren van een optimale subset van kenmerken uit een gegeven set van kenmerken; De optimale subset is de subset die de prestaties van het model voor de gegeven taak maximaliseert.
Kenmerkidentificatie kan een handmatig proces zijn of expliciet wanneer dit wordt gedaan met behulp van filtermethoden of wrappermethoden. Bij deze methoden worden kenmerken iteratief toegevoegd of verwijderd op basis van de waarde van een vaste metriek. Deze bepaalt hoe belangrijk het kenmerk is voor het doen van een voorspelling. De metriek kan bestaan uit informatieverwerving, variantie of chi-kwadraatstatistieken. Het algoritme beslist of een kenmerk wordt geaccepteerd of afgewezen op basis van een vaste drempelwaarde voor de metriek. Opgemerkt dient te worden dat deze methoden geen deel uitmaken van de modeltrainingsfase, maar daaraan voorafgaan.
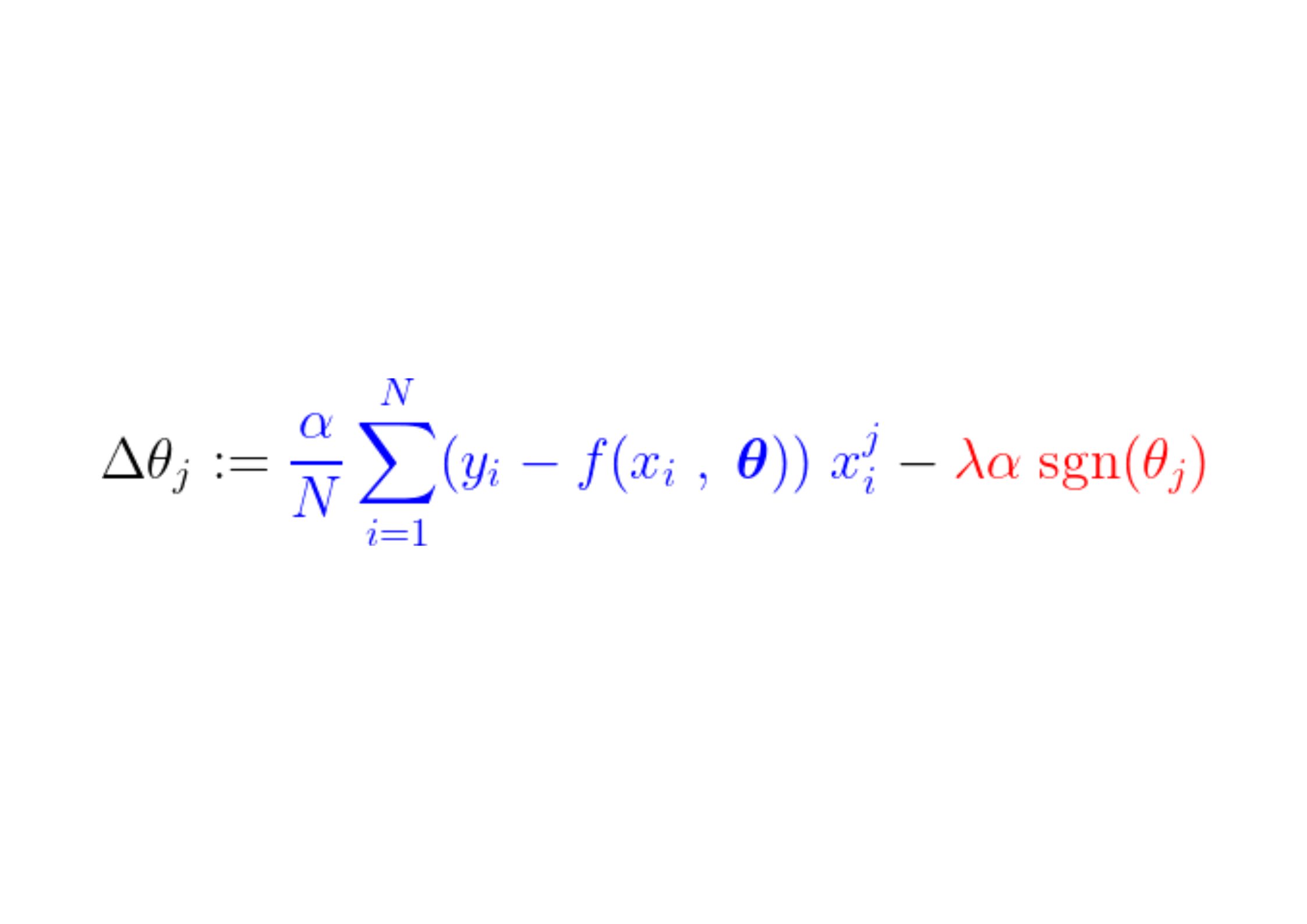
sta op Ingebedde methoden Door kenmerken impliciet te selecteren, zonder gebruik te maken van vooraf gedefinieerde selectiecriteria, en ze uit de trainingsgegevens zelf te halen. Het identificeren van essentiële kenmerken is een onderdeel van de modeltrainingsfase. Het model leert kenmerken te identificeren en tegelijkertijd relevante voorspellingen te doen. In de volgende paragrafen beschrijven we de rol van regularisatie in dit essentiële kenmerkselectieproces, waarbij we ons richten op L1-regularisatie en de rol ervan bij het verbeteren van machine learning-modellen.
Normalisatie en modelcomplexiteit: geavanceerde strategieën voor prestatieverbetering
Regularisatie is het proces waarbij de complexiteit van het model wordt bestraft om overfitting te voorkomen en generalisatie naar de taak te bereiken.
Hierbij is de complexiteit van het model analoog aan het vermogen ervan om zich aan te passen aan patronen in de trainingsdata. Ervan uitgaande dat er sprake is van een eenvoudig polynoommodel in 'x'tot op zekere hoogte'd'Hoe hoger de score'dVoor polynomen heeft het model een grotere flexibiliteit om patronen in de waargenomen gegevens vast te leggen. Deze verhoogde flexibiliteit kan ertoe leiden dat het model de trainingsgegevens onthoudt in plaats van de echte patronen te leren. Hierdoor is het model minder goed in staat om te generaliseren naar nieuwe gegevens.
Overfitting en underfitting
Bij het proberen een polynoommodel met graad te passen d = 2 Bij een set trainingsmonsters die zijn getrokken uit een polynoom van de derde orde met enige ruis, kan het model de steekproefverdeling niet adequaat vastleggen. Het model mist gewoonweg Flexibiliteit أو complexiteit Vereist voor het modelleren van gegevens die gegenereerd worden door polynomen van graad 3 (of hoger). Dit model zou zijn ondergeschikt Over trainingsgegevens. Onderbelasting geeft aan dat het model te eenvoudig is en de onderliggende patronen in de data niet kan vastleggen.
Als we hetzelfde voorbeeld gebruiken, nemen we nu aan dat we een model hebben met een mate van d = 6. Nu de complexiteit is toegenomen, zou het voor het model eenvoudig moeten zijn om de oorspronkelijke kubieke polynoom te schatten die is gebruikt om de gegevens te genereren (bijvoorbeeld door de coëfficiënten van alle termen met exponent > 3 in te stellen op 0). Als het trainingsproces niet op tijd wordt afgerond, blijft het model gebruikmaken van de extra flexibiliteit om de fout verder te verkleinen en ook samples met veel ruis te registreren. Dit zal de trainingsfout aanzienlijk verminderen, maar het model is nu overfits Over trainingsgegevens. Ruis verandert in de praktijk (of tijdens de testfase) en alle kennis die op voorspellingen is gebaseerd, wordt verstoord, wat tot grote testfouten leidt. Overbelasting betekent dat het model te complex is en ruis leert in plaats van het werkelijke signaal.
Hoe bepaal je de optimale complexiteit van het model?
In de praktijk hebben we vaak weinig tot geen inzicht in het proces van datageneratie of de daadwerkelijke distributie van data. Het vinden van het optimale model met de juiste complexiteit, zodat er geen onder- of overfitting optreedt, is een grote uitdaging. Hiervoor zijn effectieve methoden nodig om de prestaties van modellen te evalueren en de juiste complexiteit te bepalen die de beste balans tussen nauwkeurigheid en algemeenheid oplevert. Door gebruik te maken van geschikte evaluatiemetrieken en -technieken zoals kruisvalidatie, kunnen professionals vaststellen welk model het beste presteert op ongeziene gegevens. Zo kunnen ze over- of onderaanpassingsproblemen voorkomen.
Een mogelijke techniek is om te beginnen met een voldoende robuust model en vervolgens de complexiteit ervan te verminderen door kenmerkselectie. Hoe minder kenmerken, hoe minder complex het model.
Zoals we in de vorige sectie hebben besproken, kan kenmerkselectie expliciet (filtermethoden, convolutiemethoden) of impliciet zijn. Overbodige kenmerken die niet van groot belang zijn voor het bepalen van de waarde van de doelvariabele, moeten worden verwijderd om te voorkomen dat het model ongecorreleerde patronen in deze kenmerken leert. Regularisatie voert een vergelijkbare taak uit. Hoe verhouden regularisatie en kenmerkselectie zich tot het bereiken van het gemeenschappelijke doel van optimale modelcomplexiteit? Het verminderen van de complexiteit in machine learning-modellen is cruciaal om de prestaties te verbeteren en overfitting te voorkomen. Dit is waar zowel regularisatie als kenmerkselectie zich op richten.
L1-regularisatie als kenmerkbepaler
Als we doorgaan met ons polynoommodel, stellen we het voor als een functie f, met invoer x, en transacties θ en diploma d،
![]()
Voor een polynoommodel kan elke macht van de invoer worden beschouwd x_ik Als voordeel is het om een vector van de volgende vorm te vormen:
![]()
We definiëren ook een objectieve functie, die minimaliseert en zo tot optimale parameters leidt. * Het omvat de term regularisatie (Regulering) die de complexiteit van het model bestraft.
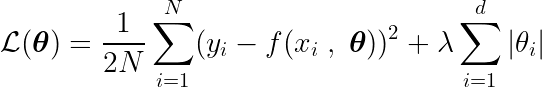
Om het minimum van deze functie te vinden, moeten we alle kritieke punten analyseren, dat wil zeggen de punten waar de afgeleide nul of ongedefinieerd is.
De partiële afgeleide kan worden geschreven met betrekking tot een van de parameters, θj, Als volgt:
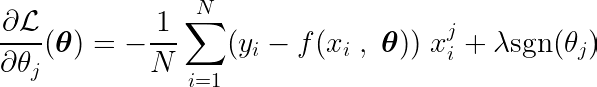
waar de functie is gedefinieerd gn Als volgt:
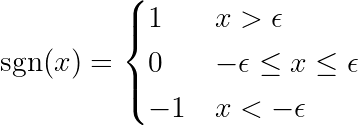
opmerkingDe afgeleide van een absolute functie verschilt van de tekenfunctie (sgn) die hierboven is gedefinieerd. De oorspronkelijke afgeleide is ongedefinieerd bij x = 0. We breiden de definitie uit om het buigpunt bij x = 0 te verwijderen en de functie over het gehele bereik differentieerbaar te maken. Bovendien maken machine learning (ML)-frameworks gebruik van deze uitgebreide functies wanneer de onderliggende berekeningen de absolute functie omvatten. Kijk hier eens naar! الرابط In het PyTorch-forum.
Door de partiële afgeleide van de doelfunctie te berekenen met betrekking tot een enkele coëfficiënt θjen door deze gelijk te stellen aan nul, kunnen we een vergelijking opstellen die de optimale waarde van θj Met voorspellingen, doelen en functies.
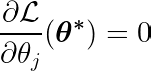
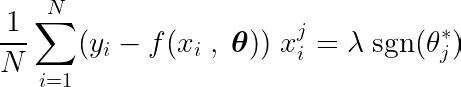
Laten we de bovenstaande vergelijking eens bekijken. Ervan uitgaande dat de invoer en de doelen rond het gemiddelde waren gecentreerd (dat wil zeggen dat de gegevens in de voorverwerkingsstap waren gestandaardiseerd), vertegenwoordigt de term aan de linkerkant (LHS) effectief variantie Tussen kenmerknummer j en het verschil tussen de verwachte en de gewenste waarde.
Statistische covariantie tussen twee variabelen bepaalt hoeveel invloed de ene variabele heeft op de waarde van de tweede variabele (en vice versa).
De tekenfunctie aan de rechterkant dwingt de variatie aan de linkerkant om slechts drie waarden aan te nemen (aangezien de tekenfunctie alleen -1, 0 en 1 retourneert). Als de functie j Onnodig en heeft geen invloed op de voorspellingen, de variantie zal dicht bij nul liggen, waardoor de overeenkomstige coëfficiënt θj* Nul. Dit heeft tot gevolg dat de feature uit het model wordt verwijderd. Dit proces helpt de complexiteit te verminderen en de modelprestaties te verbeteren.
Stel je voor dat het bord functioneert als een groef die door water is uitgeslepen. Je kunt de kloof (de rivierbedding) inlopen, maar om er weer uit te komen zul je enorme obstakels of steile stroomversnellingen tegenkomen. L1-regularisatie creëert een “drempel”-effect dat vergelijkbaar is met de gradiënt van de verliesfunctie. De helling moet sterk genoeg zijn om de barrières te doorbreken of nul te worden, waardoor de coëfficiëntwaarde uiteindelijk nul wordt.
Om een realistischer voorbeeld te geven: neem een dataset met samples afgeleid van een rechte lijn (geparameteriseerd met twee factoren) met wat toegevoegde ruis. Het optimale model mag niet meer dan twee parameters hebben, anders zal het model overmatig worden aangepast aan de ruis in de data (met de extra vrijheid/macht van de polynoom). Het wijzigen van de hogere vermogenscoëfficiënten in een polynoommodel heeft geen invloed op het verschil tussen de doelen en de modelvoorspellingen en vermindert zo hun variantie met de eigenschap.
Tijdens het trainingsproces wordt een vaste stap toegevoegd of afgetrokken van de helling van de verliesfunctie. Als de gradiënt van de verliesfunctie (MSE – gemiddelde kwadratische fout) kleiner is dan de constante stap, zal de coëfficiënt uiteindelijk een waarde van 0 bereiken. Let op de onderstaande vergelijking, die laat zien hoe de coëfficiënten worden bijgewerkt met behulp van gradiëntdaling:

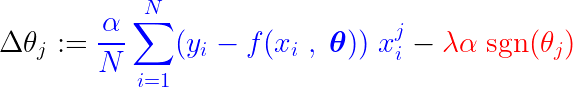
Als het blauwe gedeelte hierboven kleiner is dan λα, wat op zichzelf een heel klein aantal is, dan Δθj Het is bijna een gestage stap. λα. Het signaal voor deze stap (rode gedeelte) is afhankelijk van: sgn(θj), waarvan de output afhankelijk is van θj. Als de waarde is θj Positief, d.w.z. groter dan ε, de sgn(θj) is gelijk aan 1, waardoor Δθj Ongeveer gelijk aan -λα, waardoor het richting nul wordt geduwd.
Om de constante stap (rode gedeelte) die de coëfficiënt nul maakt te onderdrukken, moet de gradiënt van de verliesfunctie (blauwe gedeelte) groter zijn dan de stapgrootte. Om een grotere gradiënt voor de verliesfunctie te krijgen, moet de kenmerkwaarde de modeluitvoer aanzienlijk beïnvloeden.
Op deze manier wordt de feature, of preciezer gezegd de corresponderende parameter waarvan de waarde niet gerelateerd is aan de modeluitvoer, op nul gezet door L1-regularisatie tijdens de training.
Verder lezen en conclusie
- Om meer inzicht in dit onderwerp te krijgen, heb ik een vraag op Reddit r/MachineLearning geplaatst enOpvolgen Er staan verschillende interpretaties in die u wellicht wilt lezen.
- Madiyar Aitbayev heeft ook interessante blog Behandelt dezelfde vraag, maar met een technische uitleg.
- Blog Brian King legt organisatie uit vanuit een waarschijnlijkheidsperspectief.
- Dit Bekentenis Op de website CrossValidated legt hij uit waarom het L1-criterium schaarse modellen aanmoedigt. Blog In een uitgebreid artikel van Mukul Ranjan wordt uitgelegd waarom de L1-norm ervoor zorgt dat transacties nul worden en de L2-norm niet.
“L1-regularisatie selecteert kenmerken” is een eenvoudige stelling waar de meeste ML-leerders het mee eens zijn, zonder in te gaan op hoe het intern werkt. Met deze blog probeer ik mijn begrip en mentale model aan de lezers te presenteren, zodat zij op een intuïtieve manier antwoord kunnen geven op de vraag. Voor suggesties en twijfels kunt u mijn e-mailadres vinden op Mijn website. Blijf leren en heb een fijne dag!
Reacties zijn gesloten.