

Kunstmatige intelligentie heeft ons voor de gek gehouden met het telefoonspel... en het resultaat was schokkend!
Op AI gebaseerde modellen voor het genereren van afbeeldingen ontwikkelen zich snel, maar het komt nog steeds vaak voor dat ze twijfelachtige afbeeldingen opleveren. Omdat je al snel zou denken dat menselijke aanwijzingen het probleem vormen, besloot ik te testen of AI makkelijker werkt als er alleen gebruik wordt gemaakt van door AI gegenereerde aanwijzingen. Het genereren van afbeeldingen met behulp van kunstmatige intelligentie, zoals ChatGPT en Gemini, is sterk afhankelijk van de kwaliteit en nauwkeurigheid van de prompts. Zullen de resultaten anders zijn bij gebruik van geautomatiseerde claims? Dat is wat we in dit experiment zullen ontdekken.
![]()
Vuistregels
Toen er een paar jaar geleden AI-modellen voor beeldgeneratie opkwamen, dachten we allemaal dat dit een wake-upcall zou zijn voor iedereen die in de visuele media werkt. Maar dat was niet zo. Ondanks hun vermogen om zeer realistische afbeeldingen te creëren, vallen AI-afbeeldingen vaak in de categorie 'onverwacht', vooral als u iets complexer nodig hebt (AI heeft bijvoorbeeld vaak moeite met het genereren van afbeeldingen van handen).
Je kunt de AI-modellen zelf de schuld geven van dit probleem, of de tekortkomingen van mensen en onze inconsistente vaardigheden bij het schrijven van claims. Een natuurlijke manier om te testen wie verantwoordelijk is, is door te kijken of modellen voor het genereren van afbeeldingen betere resultaten opleveren als u gegenereerde prompts introduceert.

Kan AI ons een nieuw perspectief bieden op historische momenten?
Om deze hypothese te testen, ga ik Gemini gebruiken om een serie opdrachten te maken waarbij ik de naam van het object of de afbeelding die ik probeer te maken, vermijd. Hiermee kan worden geverifieerd hoe goed de AI de instructies ‘leest’. Toegegeven, het is nog steeds mogelijk dat het model aanzienlijke inspiratie haalt uit de data waarmee het is getraind (met name bij het opnieuw creëren van bestaande afbeeldingen), maar dat is de realiteit, zegt Young.
Mijn favoriete hulpmiddel voor het maken van afbeeldingen is Bing's (ja, Bing bestaat nog steeds) Image Creator, dat is gebaseerd op DALL-E 3. Om het model op de proef te stellen, begin ik met eenvoudige vormen en ga ik naarmate het experiment vordert over op complexere afbeeldingen.
Als je ChatGPT en dergelijke hebt gebruikt, weet je al hoe nutteloos sommige antwoorden kunnen zijn. Dat was niet anders bij de vragen die het model mij stelde tijdens een 'bèta'-run. Daarom heb ik besloten om mezelf te beperken tot 500 tekens, zodat de prompts consistent blijven.
Hoe AI omgaat met eenvoudige vormen
Laten we beginnen met een eenvoudig vierkant. Ik vroeg Gemini om een vierkant te beschrijven zonder het een naam te geven, en hij kwam met het volgende:
Een vierhoek waarvan alle zijden even lang zijn. Elke binnenhoek is precies 90 graden. Het is een regelmatige vierhoek waarvan de tegenoverliggende zijden evenwijdig zijn.
Nadat ik de beschrijving in DALL-E had ingevoerd, kreeg ik deze resultaten:
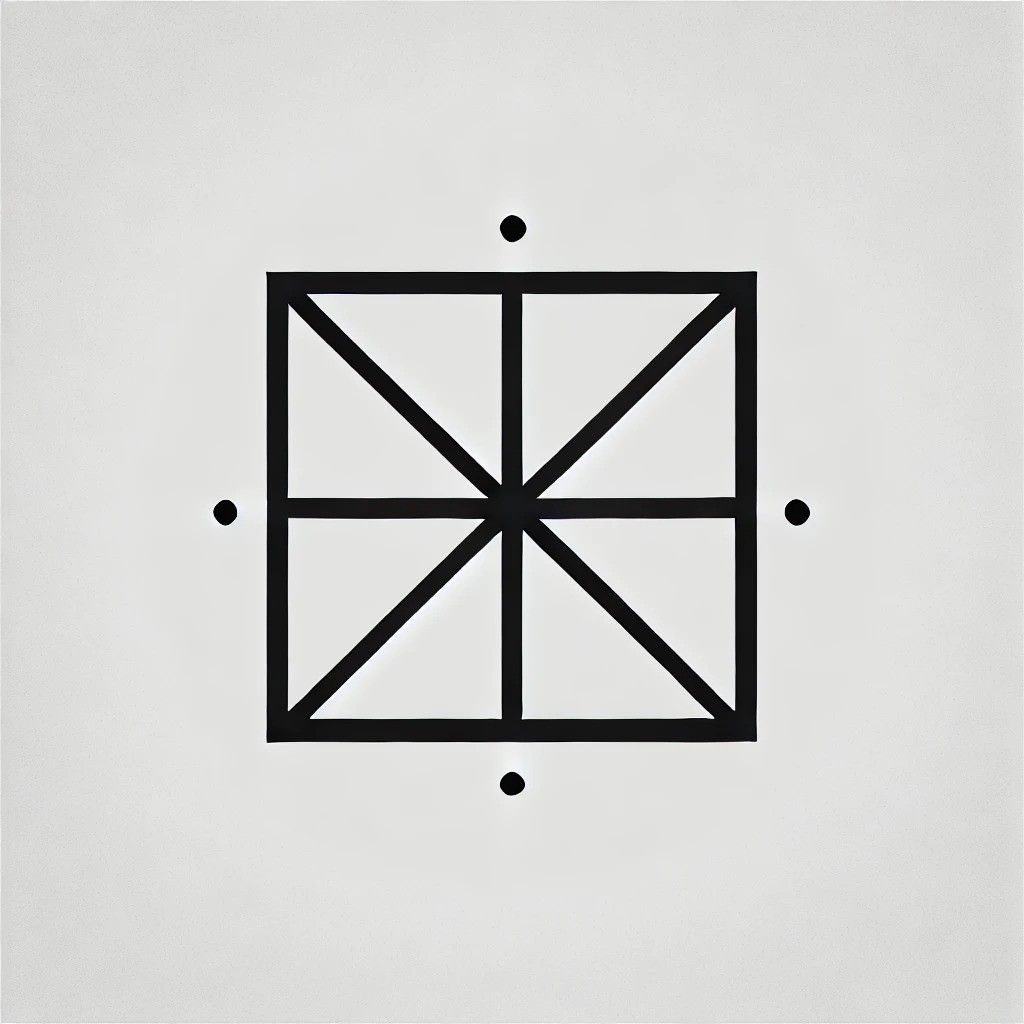
Het is een vierkant, oké, maar ik denk dat het een beetje te geometrisch is. Het werd tijd om de moeilijkheidsgraad te verhogen, dus vroeg ik de AI om een kubus uit te werken.
Een driedimensionale vorm met zes congruente vlakken. Elk vlak is een regelmatige vierhoek met vier gelijke zijden en vier rechte hoeken. Het heeft 12 even lange randen en 8 hoekpunten. Alle hoeken binnen de vorm zijn rechthoekig.
De resultaten zijn verbluffend:

Weet u nog wat we zeiden over de onvoorspelbaarheid van AI-modellen? Nou, DALL-E heeft wel een kubus ontworpen, maar raakte een beetje in de war en maakte er een Rubik's Cube van. Ondanks dat de AI het exacte woord volledig vermeed, had hij het gedeeltelijk mis – we kunnen dit toeschrijven aan de populariteit van het galactische puzzelspel.
De visie van AI op fotografie met mensen
De kubussituatie laat zien dat AI zelfs met een nauwkeurige, ‘onpartijdige’ beschrijving nog steeds vrij eenvoudige instructies verkeerd kan interpreteren. Laten we eens kijken hoe goed het presteert met door AI gegenereerde beschrijvingen van klassieke afbeeldingen, zoals "Migrant Mother" van Dorothea Lange. Hier is de originele afbeelding:

We zien een vrouw met een bezorgd gezicht wegkijken van de camera. Haar kinderen staan om haar heen, hun gezichten verborgen of afgewend. Ze legt haar hand vlak bij haar gezicht, wat uiting geeft aan haar vermoeidheid en verdriet. Het tafereel suggereert armoede en lijden. De kleding van de vrouw is slordig en de algehele compositie is somber, wat de ernst van haar omstandigheden benadrukt.
Dit is DALL-E's visie op het beroemde beeld:

Zo dichtbij! Maar het is niet helemaal accuraat, aangezien DALL-E duidelijk de zin "Omringd door haar kinderen, hun gezichten verborgen of afgewend.In plaats van dat de ‘moeder’ haar hand bij haar gezicht hield, nam een van de kinderen deze rol op zich.
Laten we het eens iets ingewikkelder proberen. Je hebt misschien de beroemde foto “Lunch bovenop een wolkenkrabber” gezien:

Elf mannen zitten hoog boven op een stalen balk te lunchen, hun benen bungelend. De balk hangt boven een uitgestrekte stad. De mannen lijken ontspannen, ondanks de extreme hoogte. Ze zijn gekleed in zakelijke kleding en de scène is vanuit een iets lagere hoek gefilmd, waardoor de hoogte wordt benadrukt.
Deze prachtige bewering heeft tot prachtige resultaten geleid:

Zodra je de klassieke kenmerken van een door AI gegenereerde afbeelding (identieke potten en "gekopieerde en geplakte" onderwerpen) negeert, wordt het bijna verrassend qua compositie en algehele uitstraling. Dat is echter niet verrassend: deze afbeelding is niet alleen heel gebruikelijk, maar ook nog eens publiek domein. Ik heb dan ook het vermoeden dat DALL-E de inhoud ervan inderdaad heeft teruggevonden tijdens de training.
Kan AI complexe beelden verwerken?
Omdat dit de laatste ‘test’ van het experiment is, is het tijd om serieus aan de slag te gaan! AI is goed in het verwerken van menselijke beelden, maar schiet vaak tekort bij complexe en dubbelzinnige scènes. En hoe zit het met de beroemde "Earthrise"-foto, genomen vanuit een baan om de maan tijdens Apollo 8?

Een gedeeltelijk verlichte bol hangt in een donkere ruimte. Een kleinere, grijze bol rijst boven de horizon uit. De grotere bol vertoont blauwe en witte vlekken, die water en wolken suggereren. Het sterke contrast tussen de twee bollen en het zwart benadrukt de kwetsbaarheid en isolatie van de kleinere, oprijzende bol.
Gemini (of beter gezegd bal) schiet tekort in deze beschrijving. Omdat het te abstract was, voegde ik de zin "gevangen in een baan nabij de maan" toe aan de bewering, maar dat hielp niet veel:

Het is een coole, progressieve rockalbumhoes, maar het heeft niets te maken met Earthrise. Om het experiment af te ronden, koos ik de tot nu toe meest mysterieuze afbeelding: Edward Westons industriële meesterwerk “Armco Steel”:

Een reeks ronde, industriële metalen tanks vult het frame. Hun vormen zijn zacht en bolvormig, waardoor een repetitief patroon ontstaat. Licht weerkaatst op de oppervlakken, waardoor de gebogen vormen worden benadrukt en een gevoel van volume ontstaat. De compositie richt zich op de abstracte aspecten van industriële objecten, met de nadruk op vorm en textuur in plaats van functie. De scène is eenvoudig en modern, met een sterke nadruk op licht en schaduw.
Dit lijkt een goed artikel. Laten we eens kijken of Dall-E het met ons eens is:

Hoewel ik de sciencefictionsfeer wel kan waarderen, lijkt het totaal niet op het origineel. Ik wilde het experiment niet compleet laten mislukken, dus besloot ik de machine een handje te helpen door de term "foto uit de jaren twintig" aan het einde van het bericht toe te voegen.
Ik dacht dat deze specifieke term het beeld waar ik naar verwees, zou kunnen verduidelijken. Helaas stelde Dall-E mij opnieuw teleur en maakte opnieuw een hoes voor een progressief rockalbum:

De resultaten van dit experiment waren interessant en de conclusie die we kunnen trekken is dat AI-beeldgeneratie zeer onvoorspelbaar is, vooral bij meer abstracte concepten. Het maakt niet uit of de invoer door AI is gegenereerd en nauwkeurig is, of door mensen is gegenereerd en onvolmaakt is: de resultaten lijken willekeurig.
Dus de volgende keer dat u uzelf en uw invoerstijl de schuld geeft, bedenk dan dat de resultaten waarschijnlijk vrijwel hetzelfde zullen zijn, zelfs als er twee apparaten met elkaar communiceren.
Reacties zijn gesloten.