

Verbetering van de detectie in Transformer-modellen door het toevoegen van trainingsruis
Moderne Transformer-visiemodellen voegen ruis toe om de detectieprestaties van 2D- en 3D-objecten te verbeteren. In dit artikel leggen we uit hoe dit mechanisme werkt en bespreken we de bijdrage ervan aan het verbeteren van de nauwkeurigheid van objectdetectiemodellen. Hierbij ligt de nadruk op het gebruik van technieken zoals ruisverwijdering in het trainingsproces.

Transformatormodellen voor vroeg zicht
DETR – DEtection TRansformer (Carion, Massa et al. 2020), een van de eerste Transformer-architecturen voor objectdetectie, gebruikte geleerde encoder-decoderquery's om detectie-informatie uit afbeeldingstokens te extraheren. Deze query's werden willekeurig geïnitialiseerd en de architectuur legde geen beperkingen op die de query's dwongen om anker-achtige objecten te leren. Hoewel met Faster-RCNN vergelijkbare resultaten werden behaald, was het nadeel de langzame convergentie: er waren 500 epochs nodig om het te trainen (DN-DETR, Li et al., 2024). Recentere DETR-gebaseerde architecturen maakten gebruik van vervormbare pooling, waardoor query's zich alleen op specifieke regio's in de afbeelding konden richten (Zhu et al., Deformable DETR: Deformable Transformers For End-To-End Object Detection, 2020), terwijl andere architecturen (Liu et al., DAB-DETR: Dynamic Anchor Boxes Are Better Queries For DETR, 2022) gebruikmaakten van ruimtelijke ankers (gegenereerd met k-means, op een manier die vergelijkbaar is met ankergebaseerde CNN's), die waren gecodeerd in de eerste query's. De skip-verbindingen dwingen het Transformer-decoderblok om de vierkanten als hellingwaarden van de ankers te leren. Vervormbare aandachtslagen maken gebruik van vooraf gecodeerde ankers om ruimtelijke kenmerken uit de afbeelding te bemonsteren en deze te gebruiken om aandachtstokens te genereren. Tijdens de training leert het model welke ankers het beste gebruikt kunnen worden. Met deze aanpak leert het model om kenmerken zoals de boxgrootte expliciet in zijn query's te gebruiken.
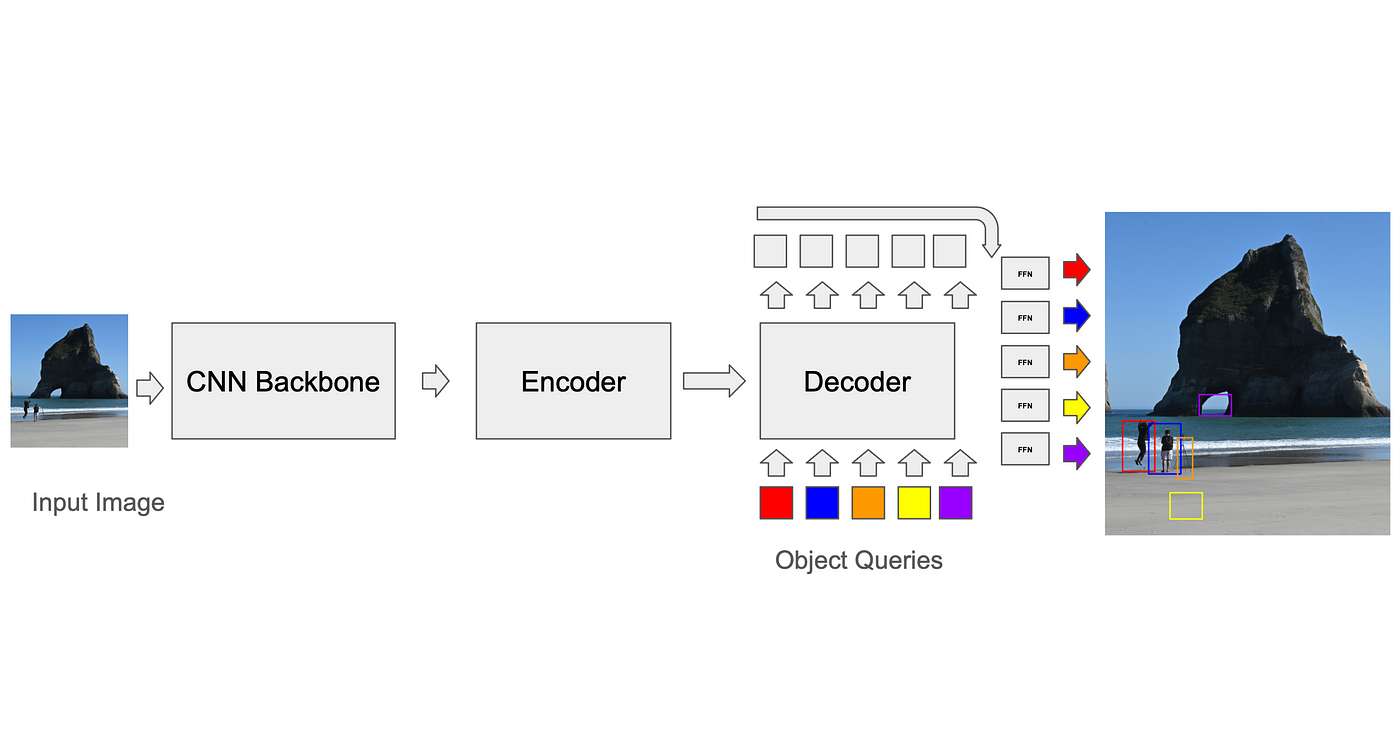
Voorspellingen matchen met grondfeiten: binair matchingalgoritme
Om het verlies te berekenen, moet de trainer eerst de voorspellingen van het model afstemmen op de grondwaarheidsvakken (GT). Hoewel ankergebaseerde CNN's relatief eenvoudige oplossingen voor dit probleem hebben (zo kan elk anker alleen worden gekoppeld aan GT-boxen in zijn eigen voxel tijdens de training, en wordt bij inferentie niet-maximale onderdrukking gebruikt om overlappende detecties te verwijderen), is de standaard voor transformatoren, ontwikkeld door DETR, het gebruik van een binair matchingalgoritme genaamd het Hongaarse algoritme. Bij iedere iteratie vindt het algoritme de beste match tussen de voorspelling en de grondwaarheid (een match die een kostenfunctie optimaliseert, zoals de gemiddelde kwadratische afstand tussen de hoeken van dozen, opgeteld over alle dozen). Vervolgens wordt het verlies tussen de predictor-ground-truth-paren berekend en kan dit worden teruggepropageerd. Bij overvoorspellingen (voorspellingen zonder GT-matching) is er sprake van een beperkt verlies, waardoor de betrouwbaarheidsscore wordt verlaagd. Dit proces is nodig om de nauwkeurigheid van het model te verbeteren en fouten te verminderen.
het probleem
De tijdcomplexiteit van het Hongaarse algoritme is o(n³). Interessant genoeg is dit niet per se een knelpunt in de trainingskwaliteit: The Stable Marriage Problem: An Interdisciplinary Review From The Physicist's Perspective, Fenoaltea et al., 2021, laat zien dat het algoritme instabiel is, wat betekent dat een kleine verandering in de objectieve functie kan leiden tot een grote verandering in het matchingresultaat – wat resulteert in inconsistente trainingsdoelstellingen voor de query. De praktische implicaties van transformertraining zijn dat objectquery's tussen objecten kunnen springen en dat het lang duurt om de beste functies voor convergentie te leren. Met andere woorden: de instabiliteit van het algoritme leidt tot schommelingen in het trainingsproces, waardoor het langer duurt om de beste resultaten te behalen.
DN-DETR (Objectdetectie door ruisonderdrukking)
Li et al. stelde een elegante oplossing voor het probleem van onstabiele matching voor, die later in veel andere werken werd overgenomen, waaronder DINO, Mask DINO, Group DETR en andere.
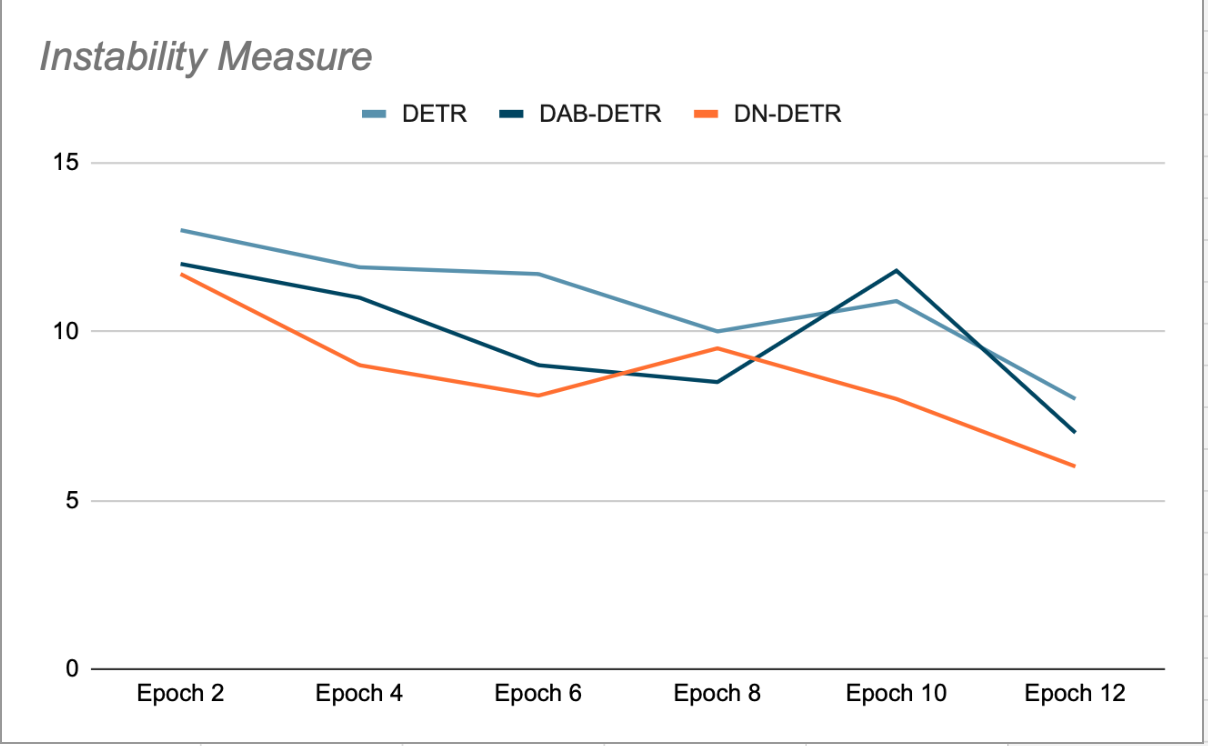
Het hoofddoel van DN-DETR is om de training te verbeteren door het creëren van Gemakkelijk te hellen denkbeeldige draaipuntenHet matchingproces wordt overgeslagen. Dit gebeurt tijdens de training door een kleine hoeveelheid ruis toe te voegen aan de GT-tegels (True Ground) en deze tegels met ruis als ankers voor decoderquery's te gebruiken. DN-query's worden gemaskeerd van organische query's en vice versa om kruisverwijzing te voorkomen die de training zou kunnen verstoren. De detecties die door deze query's worden gegenereerd, zijn al gematcht met hun bron-GT-tegels en vereisen geen bipartiete matching. De auteurs van DN-DETR hebben aangetoond dat dit tijdens de validatiefases aan het einde van elk tijdperk (waar ruisverwijdering is uitgeschakeld) de modelstabiliteit verbetert ten opzichte van DETR en DAB-DETR, wat betekent dat de Plus-query's consistent zijn in hun matching met het GT-object in opeenvolgende tijdperken (zie Afbeelding 2).
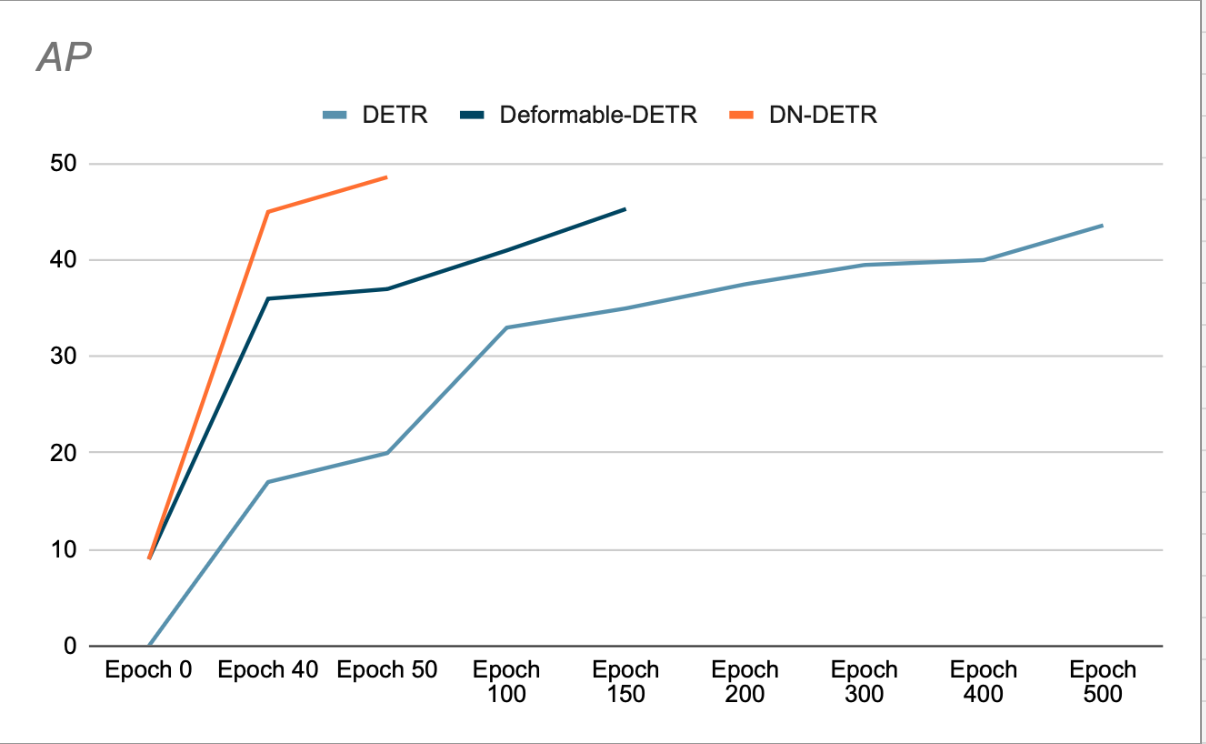
De auteurs tonen aan dat het gebruik van DN de convergentie versnelt en tot betere detectieresultaten leidt. (Zie figuur 3). Uit hun verwijderingsonderzoek blijkt dat de AP (gemiddelde nauwkeurigheid) in de COCO-detectiedataset met 1.9% is toegenomen, vergeleken met de vorige SOTA (DAB-DETR, AP 42.2%), wanneer ResNet-50 als basis wordt gebruikt.
DINO en contrastruisverwijdering
DINO heeft dit idee verder uitgewerkt en contrasterend leren toegevoegd aan het mechanisme voor ruisverwijdering: naast het positieve voorbeeld creëert DINO nog een versie met ruis van elke GT, die wiskundig zo is geconstrueerd dat deze verder van de GT verwijderd is dan het positieve voorbeeld (zie Afbeelding 4). Deze versie wordt gebruikt als een negatief voorbeeld voor training: het model leert de detectie te accepteren die het dichtst bij de grondwaarheid ligt, en de detectie die verder weg ligt te verwerpen (door te leren de klasse “geen object” te voorspellen).
Bovendien maakt DINO meervoudige clustering voor contrastieve ruisverwijdering (CDN) mogelijk – meerdere ruisende ankers voor elk GT-object – waardoor u het maximale uit elke trainingsiteratie haalt.
De DINO-auteurs rapporteerden een gemiddelde nauwkeurigheid (AP) van 49% (op COCO val2017) bij gebruik van een CDN.
Moderne temporele modellen die objecten van frame tot frame moeten volgen, zoals Sparse4Dv3, gebruiken CDN's en voegen temporele ruisonderdrukkingsgroepen toe, waarbij enkele succesvolle DN-ankers worden opgeslagen (samen met de geleerde niet-DN-ankers) voor gebruik in volgende frames, wat de prestaties van het model bij het volgen van objecten verbetert.

مناقشة
Het lijkt erop dat denoising (DN) de convergentiesnelheid en de uiteindelijke prestatie van vision-transformatordetectoren verbetert. Bij het bestuderen van de ontwikkeling van de verschillende hierboven genoemde methoden rijzen echter de volgende vragen:
- DN verbetert modellen die gebruikmaken van leerbare ankers. Maar zijn leerbare ankers echt belangrijk? Zal DN ook modellen verbeteren die gebruikmaken van niet-leerbare ankers?
- De belangrijkste bijdrage van DN aan de training is het vergroten van de stabiliteit van het gradiëntafdalingsproces door bipartite matching te omzeilen. Maar binaire matching lijkt vooral te bestaan omdat de norm bij transformerwerk is om ruimtelijke beperkingen bij query's te vermijden. Als we de query's handmatig beperken tot specifieke afbeeldingslocaties en binaire matching achterwege laten (of een vereenvoudigde versie van binaire matching gebruiken, die op elke afbeeldingspatch afzonderlijk wordt uitgevoerd), zal DN dan nog steeds de resultaten verbeteren?
Ik kon geen werken vinden die een duidelijk antwoord gaven op deze vragen. Mijn hypothese is dat een model dat gebruikmaakt van niet-leerbare ankers (mits de ankers niet te schaars zijn) en ruimtelijk beperkte query's, 1 – geen binair matchingalgoritme nodig heeft, en 2 – geen baat zal hebben bij DN tijdens de training, omdat de ankers al bekend zijn en er geen winst is in het leren van regressie van andere vluchtige ankers.
Als de ankers vastzitten maar verspreid liggen, kan ik me voorstellen dat het gebruik van tijdelijke ankers het afdalen makkelijker maakt en een goede start van het trainingsproces kan bieden.
Anchor-DETR (Wand et al., 2021) vergelijkt de ruimtelijke distributie van leerbare en niet-leerbare ankers en de prestaties van de respectievelijke modellen. Naar mijn mening voegt leerbaarheid niet veel waarde toe aan de prestaties van het model. Het is belangrijk om op te merken dat ze in beide methoden het Hongaarse algoritme gebruiken. Het is dus onduidelijk of ze de binaire matching kunnen afschaffen en toch de prestaties kunnen behouden.
Er moet rekening mee worden gehouden dat er productieve redenen kunnen zijn om NMS bij inferentie te vermijden, wat het gebruik van het Hongaarse algoritme bij training aanmoedigt.
Wanneer kan ruisonderdrukking echt van belang zijn? Naar mijn mening - in Traceerbaarheid. Bij tracking wordt het model voorzien van een videostream en moet het niet alleen meerdere objecten in opeenvolgende frames detecteren, maar ook de unieke identiteit van elk gedetecteerd object behouden. Tijdelijke transformatormodellen, dat wil zeggen modellen die gebruikmaken van de sequentiële aard van videostreaming, verwerken afzonderlijke frames niet onafhankelijk van elkaar. In plaats daarvan wordt een bank bijgehouden waarin eerdere ontdekkingen worden opgeslagen. Tijdens de training wordt het trackingmodel aangemoedigd om terug te gaan naar de vorige objectdetectie (of preciezer: naar de fixator die is gekoppeld aan de vorige objectdetectie), in plaats van simpelweg terug te gaan naar de dichtstbijzijnde fixator. Omdat de eerdere ontdekking niet beperkt is tot een vast netwerk van stabilisatoren, is het aannemelijk dat de door DN gestimuleerde flexibiliteit gunstig is. Ik zou heel graag toekomstige werken lezen die deze kwesties behandelen.
Dat is alles over ruisonderdrukking en de bijdrage ervan aan visietransformatoren! Als je mijn artikel leuk vond, nodigen we je uit om een aantal van mijn andere artikelen over deep learning en machine learning te bekijken en computervisie!
Reacties zijn gesloten.