

Ik heb de nieuwe functie van Gemini voor het genereren van afbeeldingen uitgeprobeerd en het is werkelijk geweldig.
Samenvatting:
- Google heeft een native beeldgeneratie en -bewerking gelanceerd met behulp van de nieuwe Gemini 2.0 Flash bèta.
- De functie is nu gratis beschikbaar in AI Studio. U kunt een reeks bij elkaar passende afbeeldingen genereren en bewerken met behulp van eenvoudige tekstopdrachten.
- U kunt elementen verwijderen en toevoegen, tekst invoegen, afbeeldingen inkleuren, een visueel verhaal maken en nog veel meer.
We horen de term 'natively multimodaal' al ruim een jaar in AI, maar bedrijven zijn tot nu toe traag geweest om het volledige multimodale potentieel van hun AI-modellen te benutten. Google heeft eindelijk zijn nieuwste prototype uitgebracht, de “Gemini 2.0 Flash Experimental”, met… Mogelijkheid om originele afbeeldingen te genereren en te bewerkenHoi.
Nu vraagt u zich misschien af: wat is het belang van het genereren van afbeeldingen? AI-afbeeldinggeneratie is al geruime tijd beschikbaar voor alle grote AI-chatbots, zoals ChatGPT. Wanneer we AI-afbeeldingen genereren op ChatGPT of Gemini, worden deze doorgestuurd naar een gespecialiseerd diffusiegebaseerd model zoals Dall-E 3 of Imagen 3. Deze modellen worden getraind op afbeeldingen en zijn uitsluitend ontworpen om afbeeldingen te genereren; Het is een uitbreiding van het hoofdmodel van AI, en geen onderdeel daarvan.
Er zijn echter linguïstische visiemodellen zoals Gemini Native multimedia, wat betekent dat het zowel tekst als afbeeldingen inherent kan begrijpen, genereren en wijzigen. Tot nu toe heeft geen enkel technologiebedrijf deze mogelijkheid voor gebruikers beschikbaar gesteld. OpenAI demonstreerde in 4 zijn eigen functie voor het genereren van afbeeldingen met GPT-2024o, maar ook deze functie werd nooit uitgebracht.
 Met de functie voor het genereren van originele afbeeldingen krijgt u: Betere coördinatie Waar multimodale modellen worden getraind op een enorme dataset van verschillende media. Deze modellen geven dus een beter begrip van concepten en tonen een bredere kennis van de wereld.
Met de functie voor het genereren van originele afbeeldingen krijgt u: Betere coördinatie Waar multimodale modellen worden getraind op een enorme dataset van verschillende media. Deze modellen geven dus een beter begrip van concepten en tonen een bredere kennis van de wereld.
Naast het genereren van afbeeldingen kunt u ze ook naadloos bewerken met behulp van eenvoudige tekstopdrachten. U kunt bijvoorbeeld een afbeelding uploaden en het model vragen om een zonnebril toe te voegen, vetgedrukte tekst in te voegen, objecten te verwijderen en meer. In tegenstelling tot diffusiemodellen, die de volledige afbeelding bij elke nieuwe opdracht opnieuw genereren, behouden native multimediamodellen hun consistentie bij meerdere bewerkingen.
Afbeeldingen maken met Gemini 2.0 Flash demo
Momenteel is de originele functie voor het maken van afbeeldingen niet beschikbaar voor openbare gebruikers. De Gemini 2.0 Flash-demo met native imagegeneratie is alleen beschikbaar op het AI Studio-platform van Google (Op bezoek komen) gratis.
Nadat we een preview van het model in AI Studio hebben bekeken, wordt het binnenkort ook op Gemini uitgebracht, zodat iedereen het kan gebruiken. Ik heb echter het nieuwe Gemini-model met de functie voor het maken van afbeeldingen uitgeprobeerd en dat was een zeer opwindende ervaring.
Eerst begon ik met een visuele gids om de consistentie van Gemini's vermogen om afbeeldingen te genereren te demonstreren. Ik heb Gemini gevraagd om een visuele handleiding te maken voor het maken van een omelet, waarbij ik voor elke stap in het proces een foto heb gemaakt.
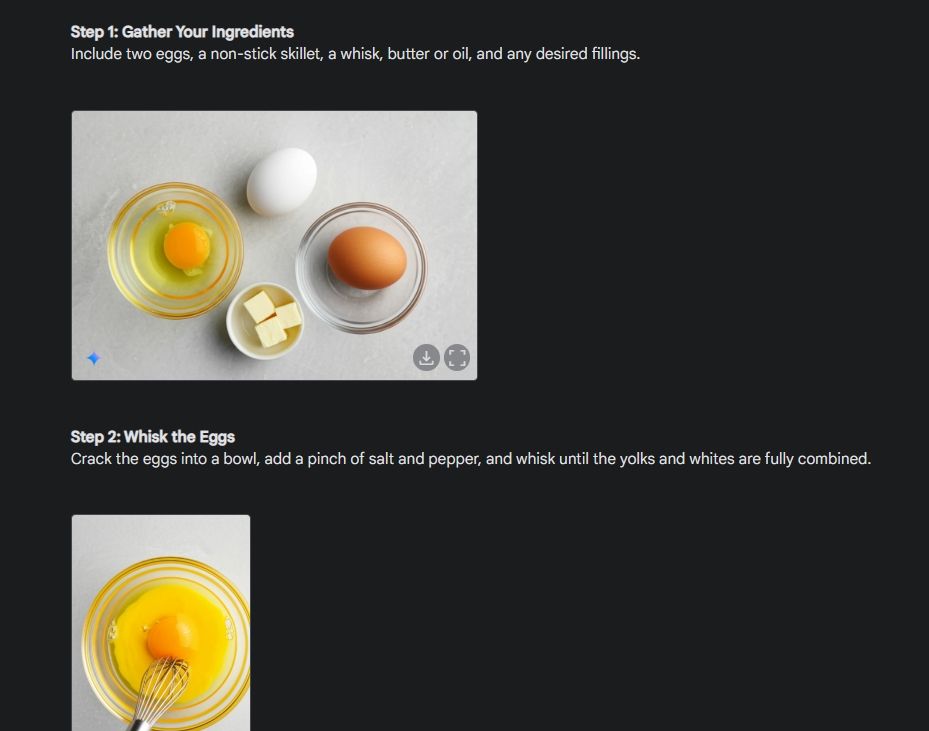
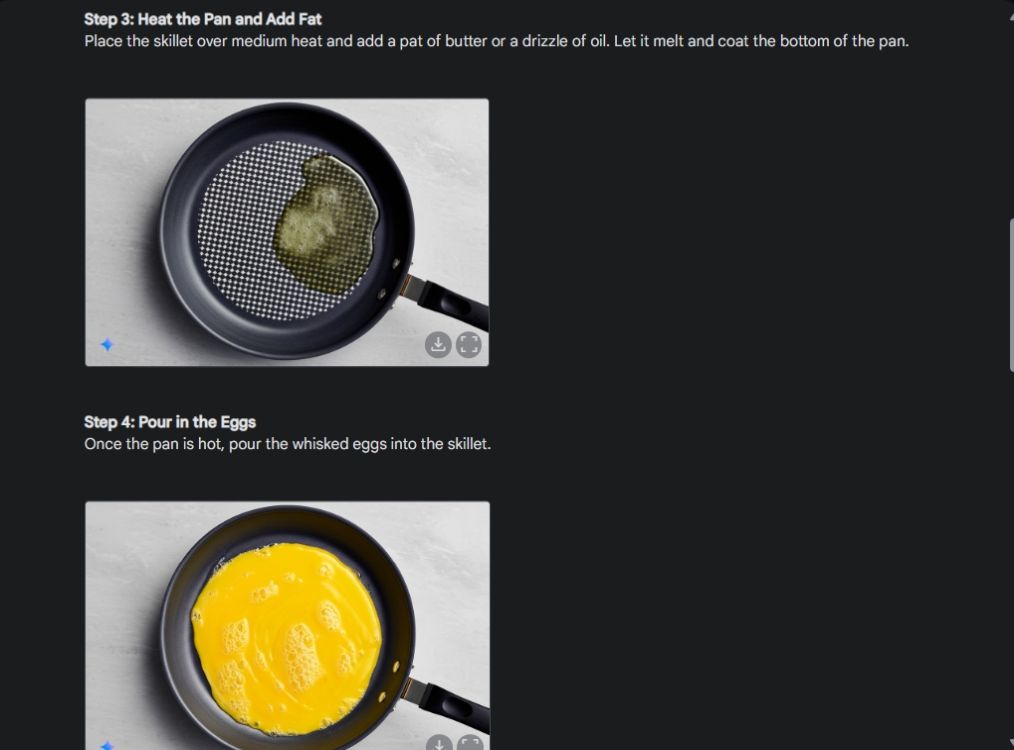

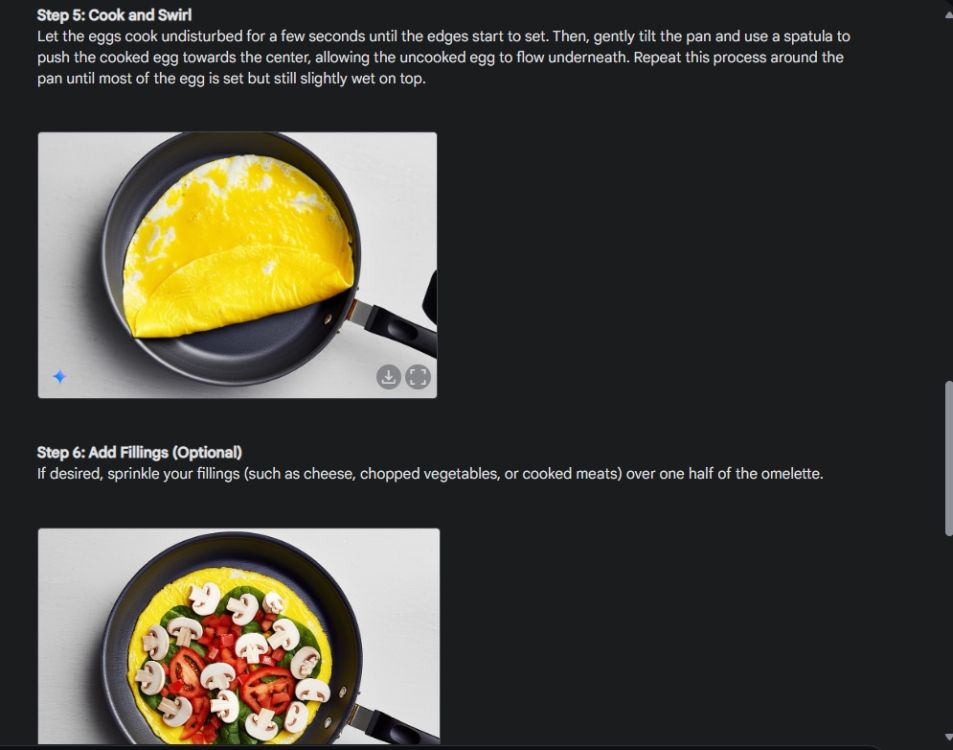
Zoals u kunt zien, zijn de resultaten over de afbeeldingen heen zeer consistent, zonder enige fout. Zelfs de kom is hetzelfde als op de tweede foto. Ten slotte kunt u afbeeldingen downloaden met een resolutie van 1024 x 680. Op deze manier kunt u een visuele gids maken voor alles wat u wilt.
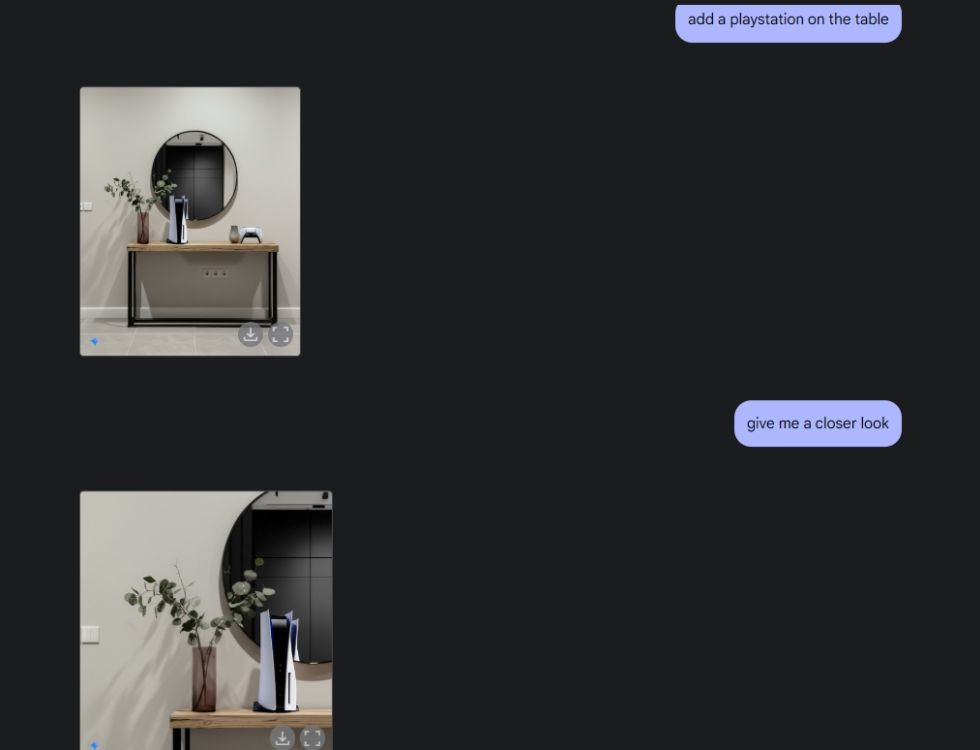
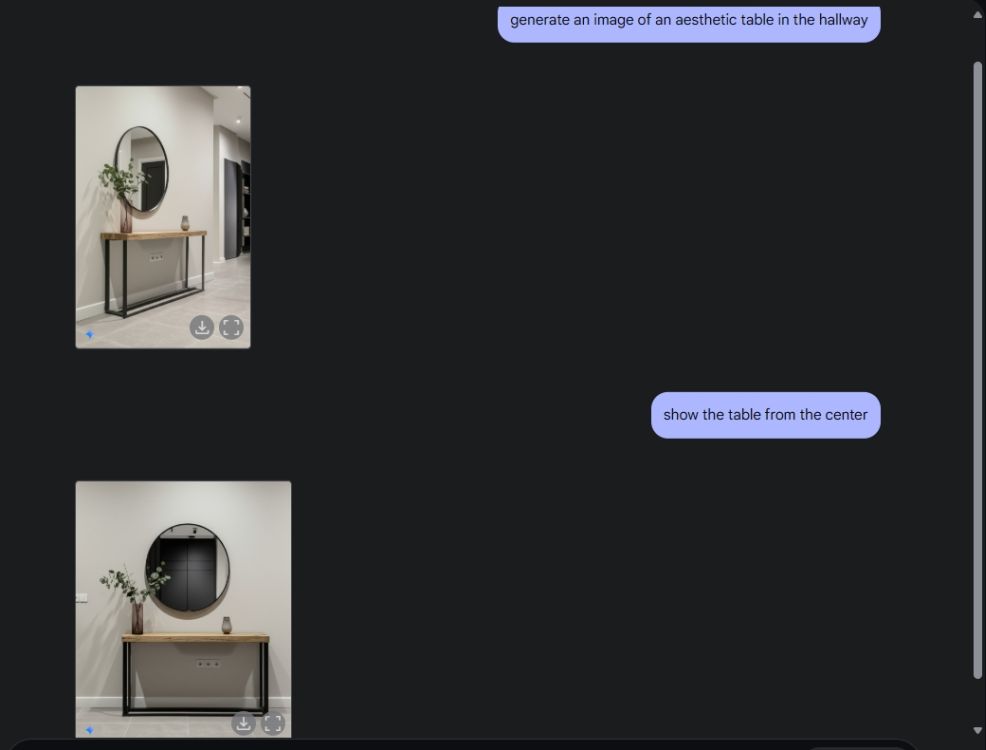
Vervolgens vroeg ik Gemini om een esthetische afbeelding van de tafel te maken en om de tafel vervolgens vanuit het middelste camerastandpunt te bekijken. Hij heeft het perfect gedaan. Vervolgens vroeg ik Gemini om een PlayStation aan de tafel toe te voegen en er eens goed naar te kijken. Gemini heeft het weer helemaal goed gedaan. Zoals je hieronder kunt zien, bevatte het AI-model ook een weerspiegeling van de PS5 in de spiegel erachter.
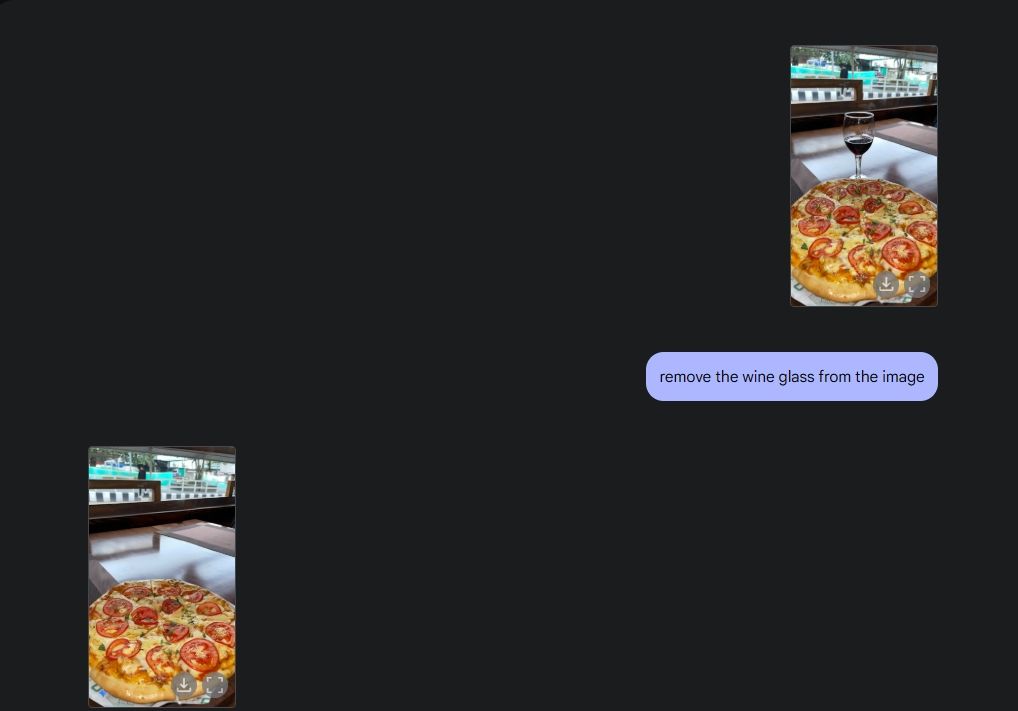
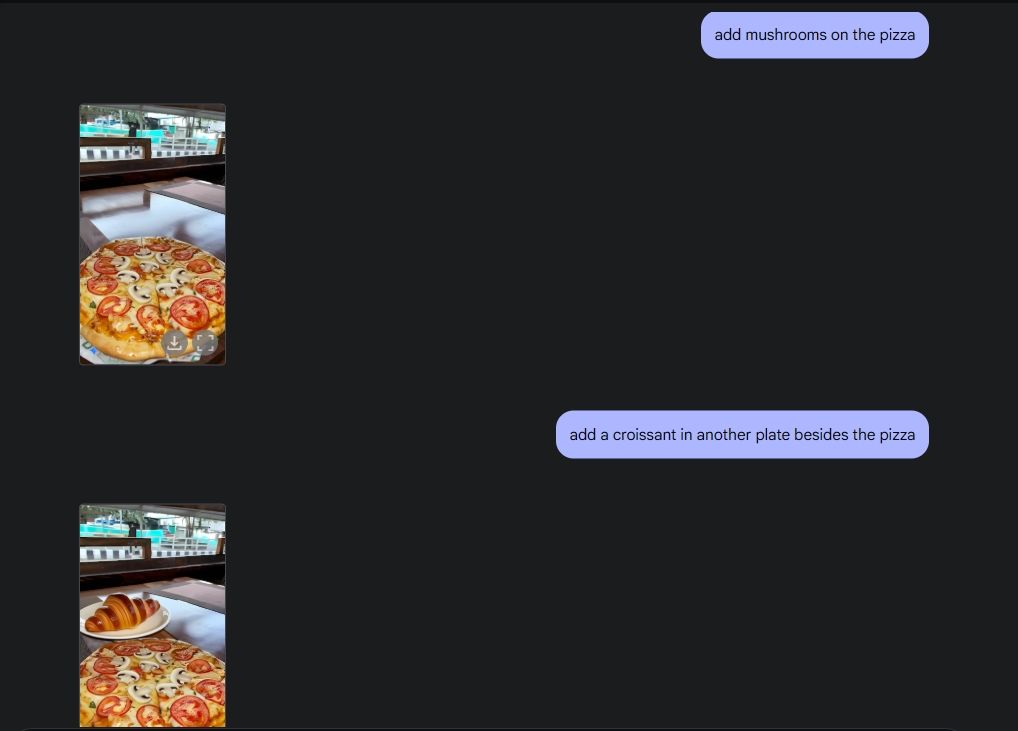
Om de originele fotobewerking te demonstreren, heb ik een foto uit mijn galerij geüpload en Gemini 2.0 gevraagd om het wijnglas van de tafel te verwijderen. Vervolgens vroeg ik Gemini om champignons aan de pizza toe te voegen en dat deed hij geweldig. Toen vroeg ik Gemini om er een croissant aan toe te voegen en voilà: AI-fotobewerking met al zijn functies, dankzij de multimediamogelijkheden van Gemini.
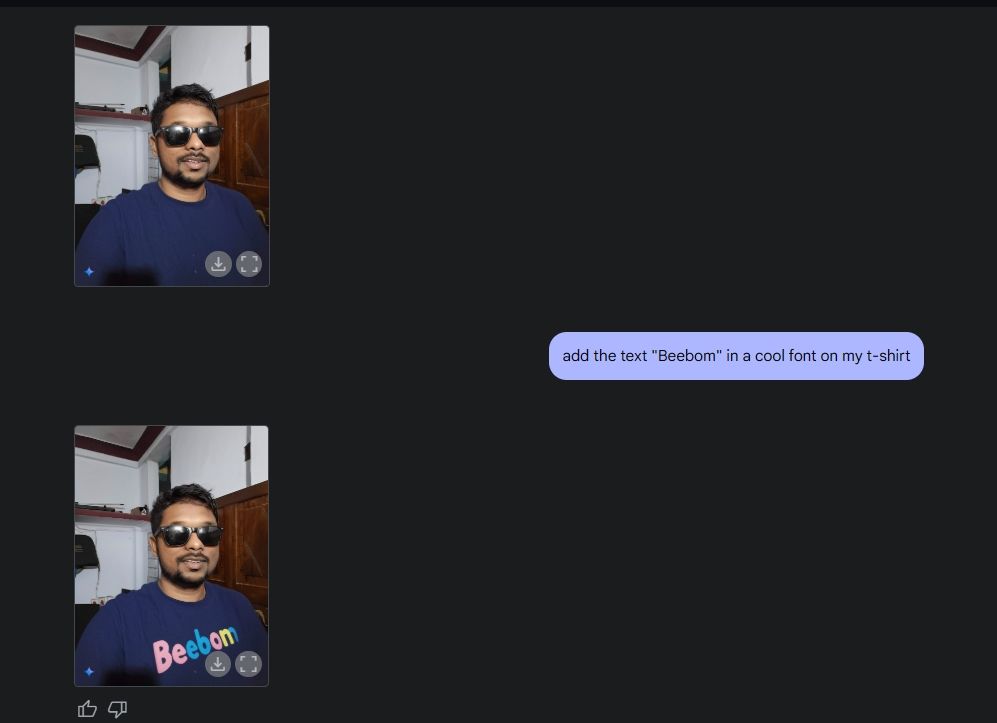
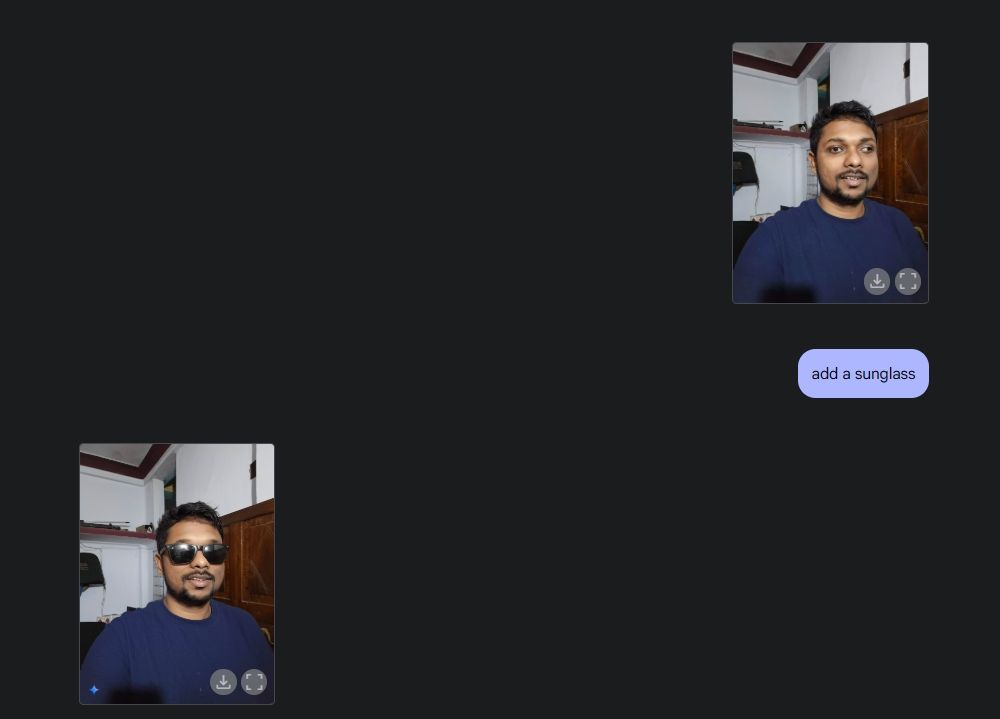
Vervolgens uploadde ik een foto van mezelf, vroeg Gemini om een zonnebril toe te voegen en voegde de tekst "Beebom" toe aan mijn shirt. Beide werden zeer goed uitgevoerd.
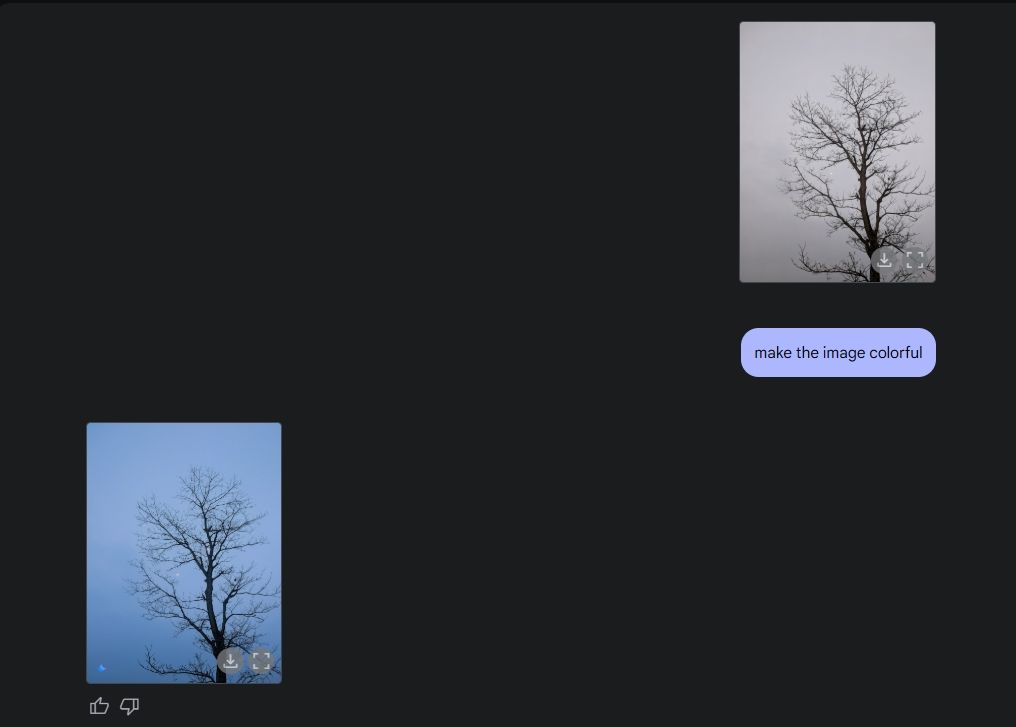
Tot slot vroeg ik Gemini om een plaatje in te kleuren, en ook dat deed hij heel goed. Ik bedoel, de foto is mooier dan voorheen, zonder vreemde fouten, vervormingen of ontbrekende delen van de foto.
Er zijn veel toepassingsmogelijkheden voor de nieuwe multimediamogelijkheden van Gemini. Google heeft geweldig werk geleverd met het maken en bewerken van afbeeldingen. Ik ben van plan om de functie de komende weken nog uitgebreider te gebruiken om de mogelijkheden ervan te testen.
Na de release van Veo 2 voor het maken van video's en Imagen 3 voor gespecialiseerde beeldcreatie, lijkt Google OpenAI op veel gebieden te hebben overtroffen; Niet alleen op het gebied van AI-tekstgeneratie. Het zal dus interessant zijn om te zien wat OpenAI gaat doen om de voorsprong met ChatGPT terug te winnen.
Reacties zijn gesloten.