
Apple wil zijn worstelende AI-model repareren door te leren van de inhoud van uw berichten.

De AI-inspanningen van Apple hebben niet dezelfde impact gehad als Gemini van Google, Copilot van Microsoft of ChatGPT van OpenAI, wat op dit gebied een uitdaging vormt voor het bedrijf. De AI-toolkit van het bedrijf, genaamd Apple-intelligentieHet bedrijf heeft niet alleen een kwalitatieve sprong voorwaarts gemaakt wat betreft de functionaliteit van zijn iPhones en Macs voor gebruikers, maar heeft ook geleid tot een interne managementcrisis binnen het bedrijf, waardoor een herevaluatie van zijn strategieën op dit gebied noodzakelijk is.
Het lijkt erop dat gebruikersgegevens de redding kunnen zijn. Vandaag publiceerde het bedrijf een onderzoeksartikel op het gebied van machinaal leren. papier Er wordt een nieuwe aanpak beschreven voor het trainen van de ingebouwde AI met behulp van gegevens die op uw iPhone zijn opgeslagen, te beginnen met e-mails. Deze berichten worden gebruikt om functies zoals e-mailsamenvattingen en schrijftools te verbeteren, de gebruikerservaring te verbeteren en de efficiëntie van deze tools te verhogen.
Korte samenvatting van AI-training
Voordat we in de details duiken, volgt hier een korte samenvatting van hoe AI-tools werken. De eerste stap is training, wat in feite inhoudt dat een "kunstmatig brein" een enorme hoeveelheid door mensen gegenereerde data krijgt toegevoerd. Denk aan boeken, artikelen, onderzoeksrapporten en meer. Hoe meer data het krijgt toegevoerd, hoe beter de reacties worden.
Dit komt doordat chatbots, technisch bekend als Large Language Models (LLM's), proberen het patroon en de relaties tussen woorden te begrijpen. Hulpmiddelen zoals ChatGPT, dat nu wordt geïntegreerd in Siri en Apple Intelligence, zijn in principe woordvoorspellingshulpmiddelen.
Er zijn echter slechts een beperkte hoeveelheid gegevens beschikbaar voor het trainen van AI, en het hele proces is erg tijdrovend en duur. Waarom zou u dan niet de door AI gegenereerde data gebruiken om uw eigen AI te trainen? Volgens onderzoek zou dat technisch gezien AI-modellen ‘vergiftigen’. Het resultaat is onjuiste antwoorden, onzin en misleidende uitkomsten.
Hoe gaat Apple zijn AI repareren?

In plaats van uitsluitend te vertrouwen op synthetische gegevens, kunnen de reacties van AI-tools worden verbeterd door ze nauwkeurig af te stemmen en te optimaliseren. De beste manier om een AI-assistent te trainen, is door hem of haar te voorzien van echte, menselijke gegevens. De gegevens op uw telefoon vormen de belangrijkste bron van deze informatie, maar het bedrijf kan dat simpelweg niet.
Dit zou een ernstige inbreuk op de privacy zijn en een uitnodiging voor rechtszaken.
Wat Apple van plan is, is om indirect naar uw e-mails te kijken, zonder ze te kopiëren of naar hun servers te sturen. Kortom, al uw gegevens blijven op uw telefoon staan. Bovendien zal Apple technisch gezien uw e-mails niet “lezen”. In plaats daarvan vergelijk je het met een reeks synthetische e-mails.
Het belangrijkste is om te bepalen welke synthetische gegevens het dichtst bij een door mensen geschreven e-mail komen. Hiermee krijgt Apple een idee van het realistischere type gegevens waarmee mensen in een gesprek te maken krijgen. Tot nu toe heeft Apple "gewoonlijk" synthetische data gebruikt om zijn AI te trainen, aldus het bedrijf. Bloomberg.
"Deze synthetische gegevens kunnen vervolgens worden gebruikt om de kwaliteit van onze modellen te testen op representatievere gegevens en om verbeterpunten te identificeren voor functies zoals samenvattingen", legt het bedrijf uit. Dit kan in de toekomst leiden tot tastbare verbeteringen in de reacties die u van Siri en Apple Intelligence krijgt.
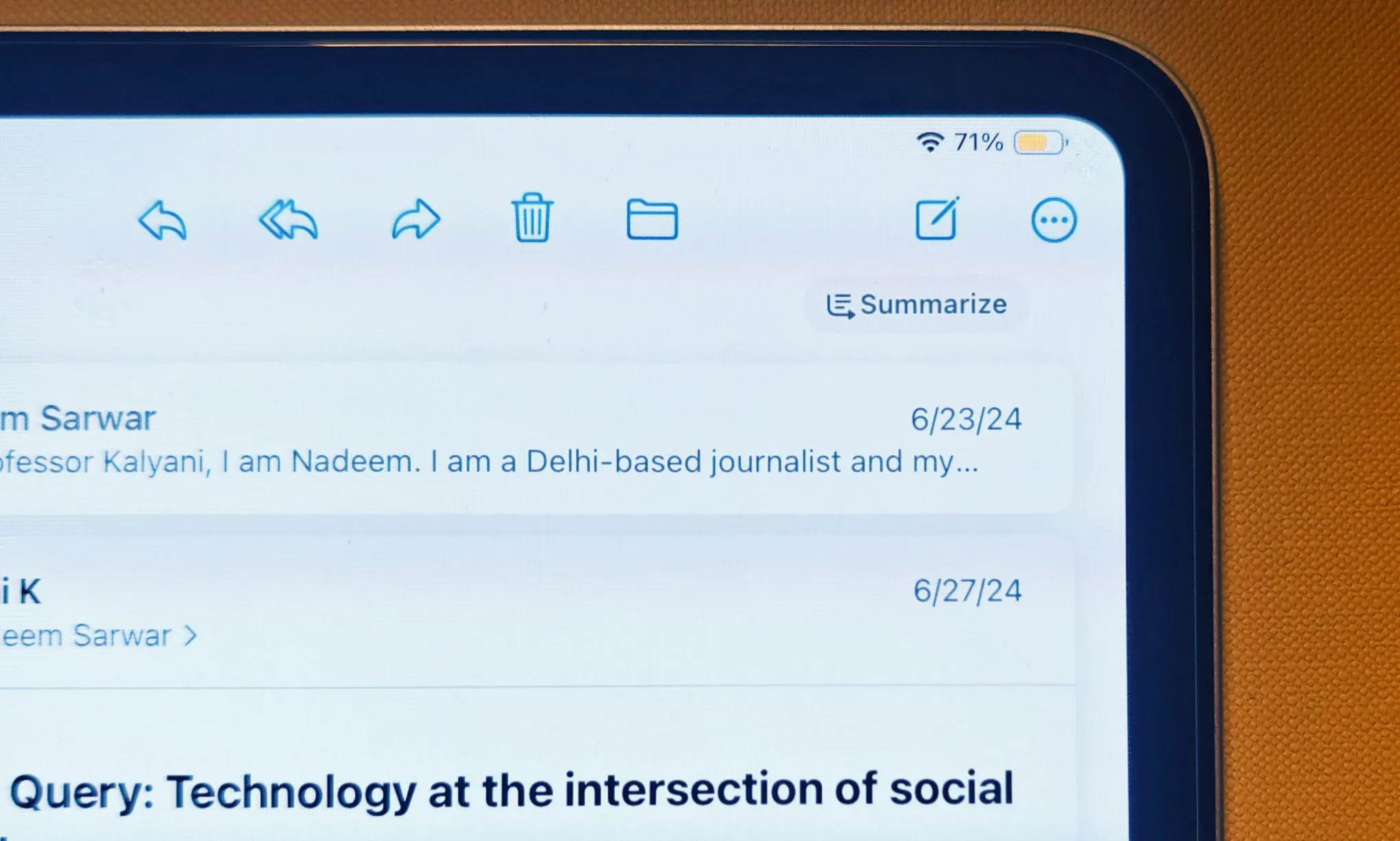
Op basis van de kennis die Apple heeft opgedaan bij het gebruik van echte menselijke gegevens, wil het bedrijf zijn systeem voor het samenvatten van e-mails en enkele elementen van zijn schrijfgereedschapskist verbeteren. Het bedrijf bevestigt dat ‘de inhoud van de bemonsterde e-mails het apparaat nooit verlaat en niet met Apple wordt gedeeld’. Apple zegt dat het al vergelijkbare, op privacy gerichte trainingssystemen heeft ingevoerd voor Genmoji.
Waarom is dit een cruciale stap voorwaarts?
Momenteel zijn de samenvattingen die u dankzij Apple Intelligence in de Mail-app krijgt vaak erg verwarrend en soms zelfs volkomen onbegrijpelijk. De huidige situatie met app-meldingen is niet anders en is zo erg geworden dat Apple ze tijdelijk heeft moeten opschorten nadat de BBC kritiek had geuit op het verkeerd weergeven van nieuwsartikelen.
De situatie is zo ernstig dat samenvattingsmeldingen in onze teamchats een grap zijn geworden. In een poging om gesprekken of e-mails samen te vatten, verzamelt Apple Intelligence vaak willekeurige zinnen die ofwel geen zin hebben, ofwel een compleet ander perspectief bieden op wat er werkelijk gebeurt. Dit heeft een negatieve invloed op de gebruikerservaring en vermindert de effectiviteit van de slimme assistent.
Het fundamentele probleem is dat AI nog steeds moeite heeft met het begrijpen van de menselijke context en intenties. De beste manier om dit op te lossen, is om hem te trainen in het gebruik van materiaal dat meer situationeel is en dat zorgt voor een goed begrip van de context. Er zijn recentelijk AI-modellen op de markt gekomen die in staat zijn om conclusies te trekken, maar deze zijn niet echt een wondermiddel. Deze nieuwe modellen beloven aanzienlijke verbeteringen in de nauwkeurigheid van het inzicht, maar vereisen nog steeds hoogwaardige trainingsgegevens.

De methode die Apple beschrijft, klinkt als het beste van twee werelden. "Met dit proces kunnen we de onderwerpen en de taal van onze synthetische e-mails verbeteren, wat ons helpt onze modellen te trainen om betere tekstuitvoer te genereren in functies zoals e-mailsamenvattingen, terwijl de privacy wordt beschermd", aldus het bedrijf. Deze aanpak combineert verbeterde prestaties met behoud van de vertrouwelijkheid van gebruikersgegevens.
En nu komt het leuke gedeelte. Apple zal niet alle e-mails lezen die op iPhones en Macs zijn opgeslagen, waar ook ter wereld. In plaats daarvan hanteren ze een abonnementsaanpak. Alleen gebruikers die expliciet toestemming hebben gegeven om Device Analytics-gegevens met Apple te delen, nemen deel aan het AI-trainingsproces. Zo hebben gebruikers volledige controle over hun gegevens.
U kunt dit inschakelen via dit pad: Instellingen > Privacy en beveiliging > Analyse en verbeteringen. Naar verluidt zal het bedrijf de plannen gaan activeren met de aankomende bèta-updates voor iOS 18.5, iPad 18.5 en macOS 15.5. Er is al een vergelijkbare versie uitgebracht die specifiek gericht is op ontwikkelaars. Hierdoor kunnen ontwikkelaars nieuwe functies testen en feedback geven om de prestaties te verbeteren.
Reacties zijn gesloten.